1. Python에서 tesseract를 이용하기
페이지 정보
작성자 관리자 댓글 0건 조회 6,826회 작성일 21-01-07 14:27본문
1. Python에서 tesseract를 이용하기
Python에서 tesseract를 이용하기 위해 관련 모듈인 Python-tesseract를 설치해줘야 한다.
GitHub - madmaze/pytesseract: A Python wrapper for Google Tesseract
Python-tesseract는 Google의 Tesseract-OCR Engine에 대한 wrapper다.
pip를 이용한 설치:
pip install pytesseract
python에서 tesseract를 사용하는 방법은 아주 간단하다. pip를 통해 설치한 pytesseract를 import하고, 앞서 설치한 tesseract 경로만 명시적으로 등록해주기만 하면 된다.
이미지로부터 텍스트를 추출하는 함수는 pytesseract.image_to_string() 이다.
파일명 : test.py
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
print(pytesseract.image_to_string('./img_08.png'))
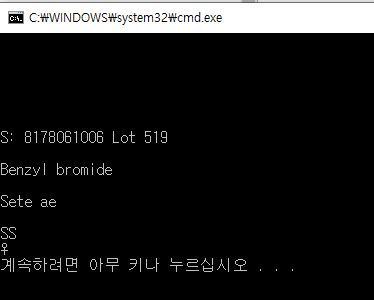
옵션을 주고 싶을 경우에는 아래와 같이 파라미터를 전달하여 함수를 호출 하면 된다.
pytesseract.image_to_string('img.png', lang='eng', config='--psm 1 -c preserve_interword_spaces=1')

그레이 스케일로 변환하기
import cv2
image = cv2.imread('2.JPG')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("원본", image)
배경에서 전경 텍스트를 분할하기 위해 임계값을 사용한다.
이러한 임계값 사용은 회색 배경 위에 겹쳐진 검은색 텍스트를 읽는 데 유용하다.
gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv2.imshow("Gray2", gray)
임계값 사용 대신, 블러(Blur) 처리를 적용될 수있다.
medianBlur를 적용하면 이미지의 노이즈를 줄일 수 있다.
gray = cv2.medianBlur(gray, 5)
cv2.imshow("medianBlur", gray)
cv2.waitKey(0)
cv2.destroyAllWindows()

