제 14 장 Tesseract 사용하기
페이지 정보
작성자 관리자 댓글 0건 조회 6,828회 작성일 21-01-07 10:11본문
제 14 장 Tesseract 사용하기
Tesseract
이미지로부터 텍스트를 인식하고, 추출하는 소프트웨어를 일반적으로 OCR이라고 한다.
Tesseract는 1984~1994년에 HP 연구소에서 개발된 오픈 소스 OCR 엔진이며, 현재까지도 LSTM과 같은 딥러닝 방식을 통해 텍스트 인식률을 지속적으로 개선하고 있다.
지금부터 Python 환경에서 Tesseract를 이용하여 이미지로부터 텍스트 추출하는 방법을 소개한다.
언어에 관계없이 Tesseract를 이용하기 위해서 우선 관련 프로그램을 설치해야 한다.
Home · UB-Mannheim/tesseract Wiki · GitHub
64비트 환경에서 tesseract-ocr-w64-setup-v5.0.0-alpha.20201127.exe 다운로드 후 설치를 진행한다.
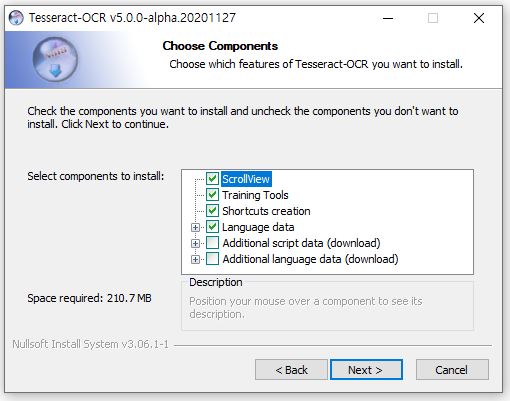
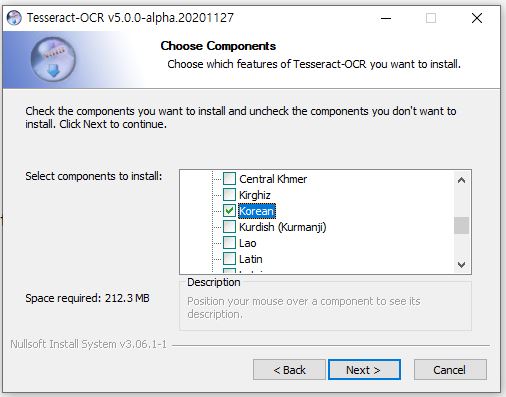
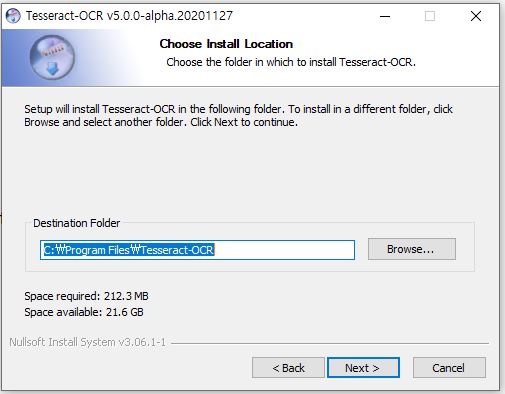
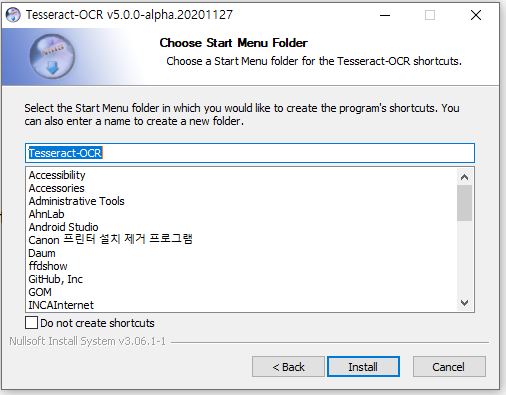
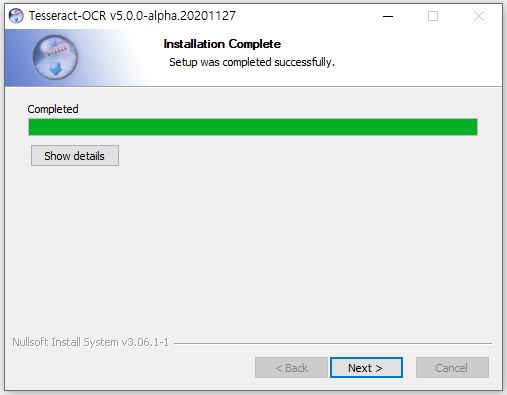
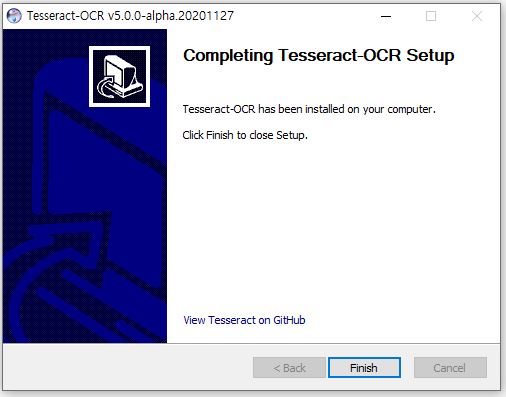
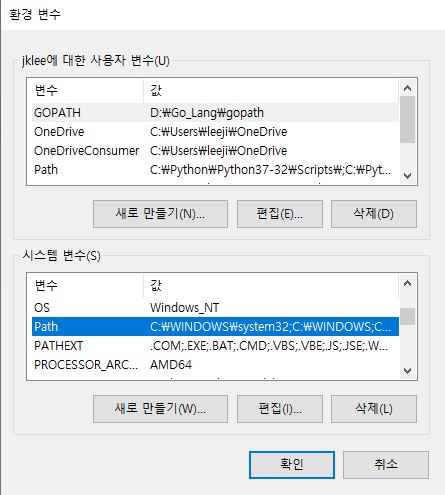
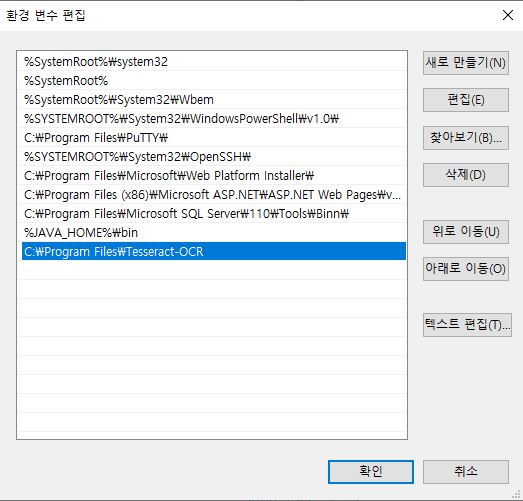
cmd창에서 tesseract 명령을 통해 정상적으로 설치되었음을 확인할 수 있다.
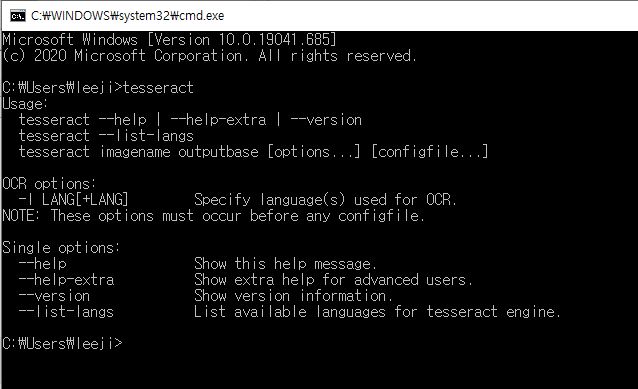
Python에서 tesseract를 사용하기 전에 직접 설치한 tesseract를 이용해 텍스트 인식 및 추출(OCR)이 잘 되는지 테스트해 볼 수 있다.
cmd 창에서 아래 명령어를 통해 특정 이미지로부터 텍스트 추출을 수행하고, 결과를 txt 파일로 저장할 수 있다.

D:\Py_Prog>tesseract IMG_08.png stdout -l eng > IMG_08.txt
D:\Py_Prog>
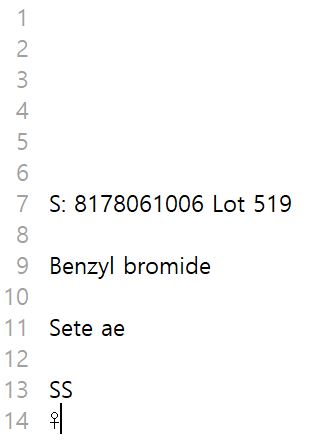
옵션 사용 시:
tesseract -c preserve_interword_spaces=1 IMG_5624.jpg stdout -l eng > IMG_5624.txt
tesseract --oem 1 --psm 7 IMG_5624.jpg stdout -l eng > IMG_5624.txt
OCR Engine modes(–oem):
0 - Legacy engine only.
1 - Neural nets LSTM engine only.
2 - Legacy + LSTM engines.
3 - Default, based on what is available.
Page segmentation modes(–psm):
0 - Orientation and script detection (OSD) only.
1 - Automatic page segmentation with OSD.
2 - Automatic page segmentation, but no OSD, or OCR.
3 - Fully automatic page segmentation, but no OSD. (Default)
4 - Assume a single column of text of variable sizes.
5 - Assume a single uniform block of vertically aligned text.
6 - Assume a single uniform block of text.
7 - Treat the image as a single text line.
8 - Treat the image as a single word.
9 - Treat the image as a single word in a circle.
10 - Treat the image as a single character.
11 - Sparse text. Find as much text as possible in no particular order.
12 - Sparse text with OSD.
13 - Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
여러 언어를 동시에 인식하고 싶을 경우에는 kor+eng 와 같이 옵션을 주면 된다.
tesseract -c preserve_interword_spaces=1 IMG_5624.jpg stdout -l kor+eng > IMG_5624.txt
텍스트 추출 결과가 아주 정확하지는 않다는 것을 확인 할 수 있다.
텍스트 추출 정확도는 이미지에 따라서 크게 차이 날 수 있다.
텍스트가 잘 정리되고 나열된 상태의 이미지라면 더 정확한 인식이 가능하다.