1. Hadoop 이란?
페이지 정보
작성자 관리자 댓글 0건 조회 4,069회 작성일 21-02-04 14:47본문
1. Hadoop 이란?
하둡은 정형데이터 및 사진영상 등의 비정형 데이터를 효과적으로 처리하는 오픈소스 빅데이터 솔루션으로, 포춘 500대 기업 모두가 하둡을 활용하고 있을 정도로 업계에서는 "빅데이터가 곧 하둡" 이라고 표현한다.
하둡 생태계가 이처럼 확장할 수 있던 요인은 아마존, 마이크로소프트, IBM, 오라클, VM웨어, 테라데이타 등의 업체들이 하둡을 적극 활용 했기 때문이다.
하둡 전문 업체인 클라우디아, 맵알테크놀로지, 호튼윅스도 우수기업과 어깨를 나란히 할 정도로 성장하였으며, 하둡 3대 업체로 불린다.
하둡관련 오픈소스 솔루션들은 해마다 발전하여 하둡과 연동된 하둡생태계를 구성하여 "하둡 에코시스템"으로 불린다.
서브 프로젝트 대부분 동물이름과 관련되어 있으며 이를 관리하는 것은 바로 주키퍼(Zookeeper)이다.
하둡 소프트웨어 라이브러리는 간단한 프로그래밍 모델을 사용하여 여러대의 컴퓨터 클러스터에서 대규모 데이터 세트를 분산 처리 할 수있게 해주는 프레임워크 이다.
단일 서버에서 수천대의 머신으로 확장 할 수 있도록 설계되었다.
일반적으로 하둡파일시스템(HDFS)과 맵리듀스(MapReduce)프레임워크로 시작되었으나, 여러 데이터저장, 실행엔진, 프로그래밍 및 데이터처리 같은 하둡 생태계 전반을 포함하는 의미로 확장 발전 되었다.
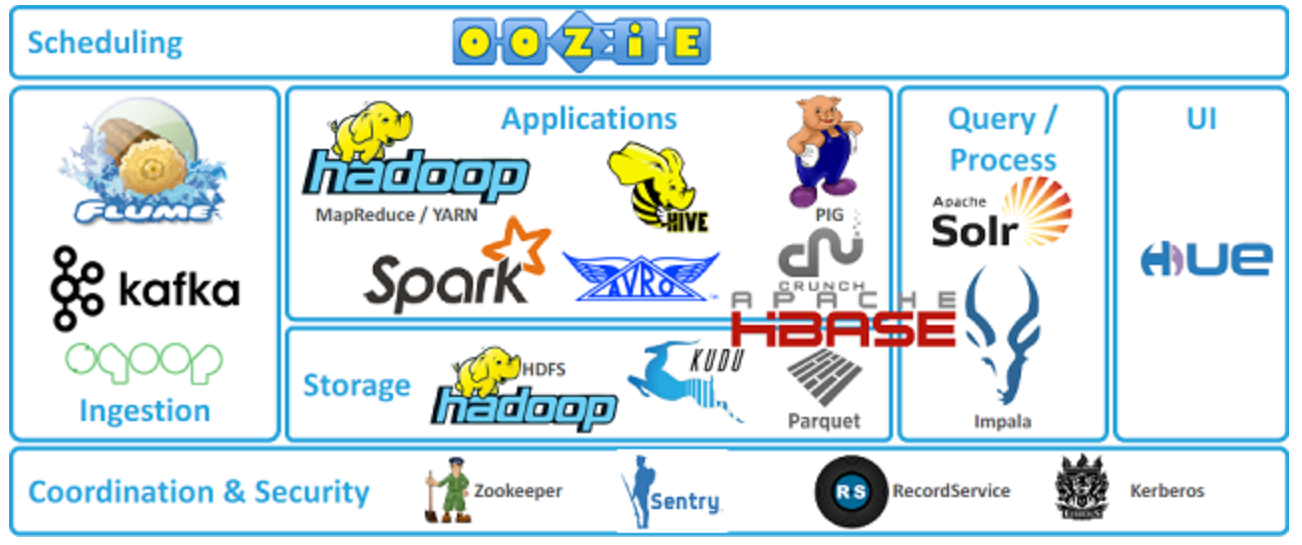
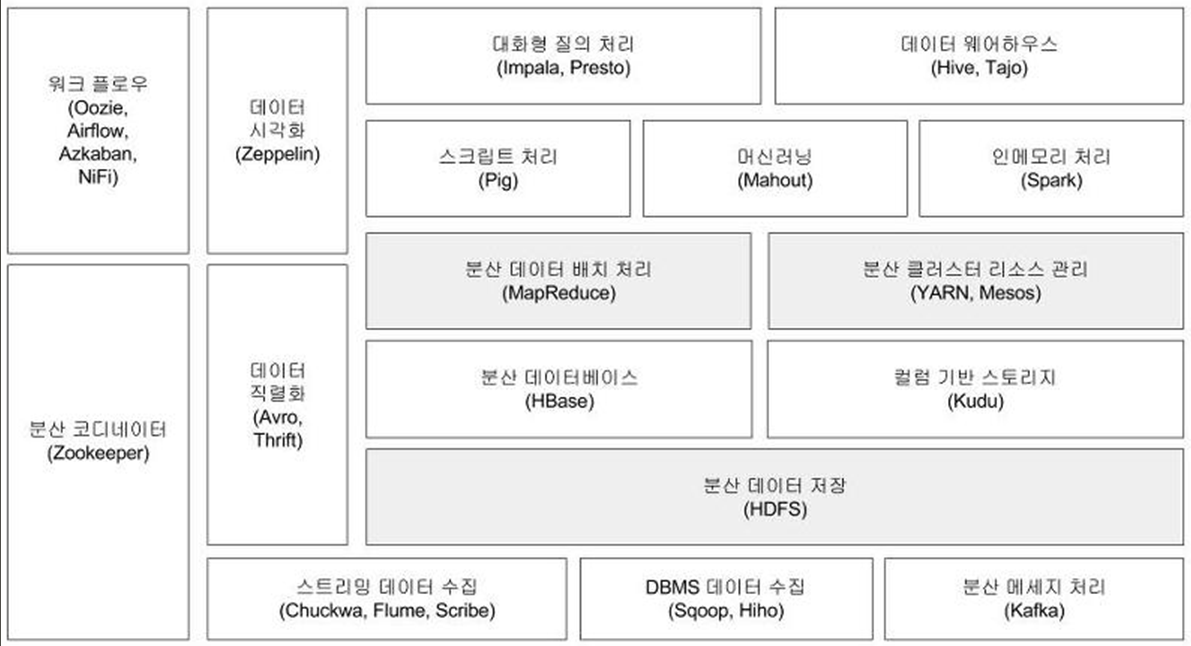
1. 분산 코디네이터
- Zookeeper
분산환경에서 서버간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템이다.
분산 동기화를 제공하고 그룹 서비스를 제공하는 중앙 집중식 서비스로 알맞은 분산처리 및 분산 환경을 구성하는 서버 설정을 통합적으로 관리 한다.
2. 분산 리소스관리
- YARN
작업 스케줄링 및 클러스터 리소스 관리를 위한 프레임워크로 맵리듀스, 하이브, 임팔라, 스파크 등 다양한 애플리케이션들은 얀에서 작업을 실행한다.
- Mesos (클라우드환경에대한 리소스관리)
Mesos는 Linux커널과 동일한 원칙을 사용하며 컴퓨터에 API(예:Hadoop,Spark,Kafka,Elasticsearch)를 제공한다
페이스북, 트위터, 이베이등 다양한 기업들이 메소스 클러스터 자원을 관리하고 있다.
3. 데이터저장
- HBase (분산 데이터베이스)
HBase는 구글 Bigtable을 기반으로 개발된 비관계형 데이터베이스이며, Hadoop및 HDFS위에 Bigtable과 같은 기능을 제공하게 된다. 네이버 라인 메신져에 HBase를 적용한 시스템 아키텍쳐를 발표 하기도 했다.
- HDFS (분산파일데이터저장)
애플리케이션 데이터에 대한 높은 처리량의 액세스를 제공하는 분산 파일 시스템
- Kudu (컬럼기반 스토리지)
컬럼기반 스토리지로 하둡 에코 시스템에 새로 추가되어 급변하는 데이터에 대한 빠른 분석을 위해 설계되었다.
클라우데라에서 시작된 프로젝트로, 15년말 아파치 인큐베이션 프로젝트로 선정 되었다.
4. 데이터수집
- Chukwa
Chukwa는 분산 환경에서 생성되는 데이터를 안정적으로 HDFS에 저장하는 플랫폼이다.
대규모 분산 시스템을 모니터링 하기 위한 시스템으로, HDFS및 MapReduce 에 구축되어 수집된 데이터를 최대한 활용하기 위한 모니터링 및 유연한 툴킷을 포함한다.
- Flume
Flume은 많은 양의 데이터를 수집, 집계 및 이동하기위한 분산형 서비스이다.
- Scribe
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와 다르게 데이터를 중앙서버로 전송하는 방식이며, 최종 데이터는 다양한 저장소로 활용할 수 있다.
- Kafka
카프카는 데이터 스트림을 실시간으로 관리하기 위한 분산 시스템으로, 대용량 이벤트 처리를 위해 개발 되었다.
5. 데이터처리
- Pig
하둡에 저장된 데이터를 맵리듀스 프로그램을 만들지 않고 SQL과 유사한 스크립트를 이용해 데이터를 처리, 맵리듀스 API를 매우 단순화한 형태로 설계 되었다 .
- Mahout
분석 기계학습에 필요한 알고리즘을 구축하기위한 오픈소스 프레임워크이며, 클러스터링, 필터링, 마이닝, 회귀분석 등 중요 알고리즘을 지원해 준다 .
- Spark
대규모 데이터 처리를 위한 빠른 속도로 실행시켜 주는 엔진이다.
스파크는 병렬 애플리케이션을 쉽게 만들수 있는 80개 이상의 고급 연산자를 제공하며 파이썬,R등에서 대화형으로 사용할 수 있다.
- Impale
임팔라는 하둡기반 분산 엔진으로, 맵리듀스를 사용하지 않고 C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여준다.
- Hive
하둡기반 데이터 솔루션으로, 페이스북에서 개발한 오픈소스로 자바를 몰라도 데이터분석을 할수 있게 도와 준다.
SQL과 유사한 HiveQL이라는 언어를 제공하여 쉽게 데이터 분석을 할 수 있게 도와 준다.
- MapReduce
MapReduce 는 대용량 데이터를 분산 처리 하기위한 프로그램으로 정렬된 데이터를 분산처리Map하고 이를 다시 합치는 Reduce 과정을 거친다.하둡에서 대용량 데이터 처리를 위한 기술중 큰 인기를 누리고 있다.