3. 신경망 실습
페이지 정보
작성자 관리자 댓글 0건 조회 3,561회 작성일 20-07-31 08:34본문
3. 신경망 실습
1. colab 설정
런타임 메뉴에서 런타임 유형 변경을 선택한다.

2. 텐서플로우 업데이트
텐서프로우의 버전은 2.0 이상을 사용한다.
버전확인 후, 2.0이하 이면 업데이트 한다.
- 삭제하기
!pip uninstall tensorflow
- 설치하기
!pip install tensorflow==2.2.0
3. fashion_mnist 데이터셋 불러오기
여기서는 운동화나 셔츠 같은 패션 이미지를 분류하는 신경망 모델을 훈련합니다.
상세 내용을 모두 이해하지 못해도 괜찮습니다.
완전한 텐서플로(TensorFlow) 프로그램의 구조를 따라 해보면서 이해하면 됩니다.
텐서플로 모델을 만들고 훈련할 수 있는 고수준 API인 tf.keras를 사용합니다.
10개의 범주(category)와 70,000개의 흑백 이미지로 구성된 패션 MNIST 데이터셋을 사용하겠습니다.
이미지는 해상도(28x28 픽셀)가 낮고 개별 패션 품목을 나타냅니다
패션 MNIST는 컴퓨터 비전 분야의 "Hello, World" 프로그램격인 고전 MNIST 데이터셋을 대신해서 자주 사용됩니다.
MNIST 데이터셋은 손글씨 숫자(0, 1, 2 등)의 이미지로 이루어져 있습니다.
여기서 사용하려는 패션 이미지와 동일한 포맷입니다.
패션 MNIST는 일반적인 MNIST 보다 조금 더 어려운 문제이고 다양한 예제를 만들기 위해 선택했습니다.
두 데이터셋은 비교적 작기 때문에 알고리즘의 작동 여부를 확인하기 위해 사용되곤 합니다.
코드를 테스트하고 디버깅하는 용도로 좋습니다.
모델을 훈련하는데 60,000개의 이미지를 사용합니다.
그다음 모델이 얼마나 정확하게 이미지를 분류하는지 10,000개의 이미지로 평가하겠습니다.
패션 MNIST 데이터셋은 텐서플로에서 바로 임포트하여 적재할 수 있습니다
load_data() 함수를 호출하면 네 개의 넘파이(NumPy) 배열이 반환됩니다:
x_train_data와 t_train_data 배열은 모델 학습에 사용되는 훈련 세트입니다.
x_test_data와 t_test_data배열은 모델 테스트에 사용되는 테스트 세트입니다.
t_train_data와 t_test_data는 레이블을 의미한다.
이미지는 28x28 크기의 넘파이 배열이고 픽셀 값은 0과 255 사이입니다.
레이블(label)은 0에서 9까지의 정수 배열입니다.
이 값은 이미지에 있는 패션의 클래스(분류)를 나타냅니다

각 이미지는 하나의 레이블에 매핑되어 있습니다.
데이터셋에 클래스 이름이 들어있지 않기 때문에 나중에 이미지를 출력할 때 사용하기 위해 별도의 변수를 만들어 저장합니다.
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
데이터셋 구조를 확인한다.

28*28 픽셀, 데이터 갯수가 6만개를 의미한다.
이미지 데이터를 출력해본다.
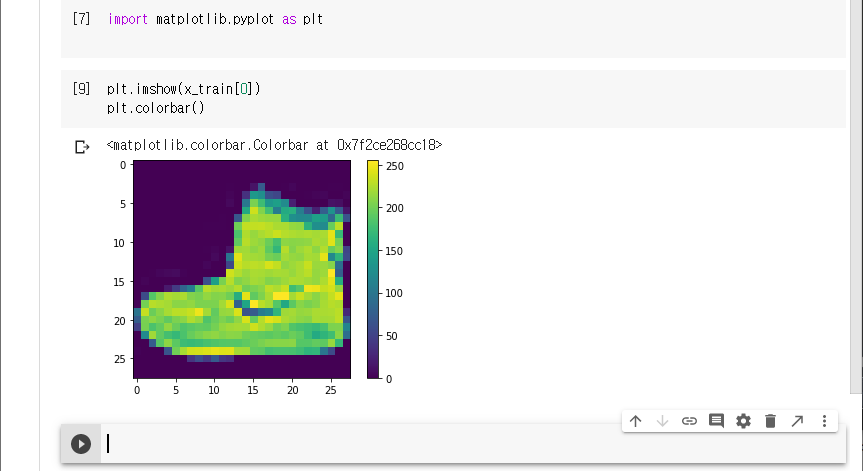
0번 이미지는 신발인 것을 확인할 수 있다.
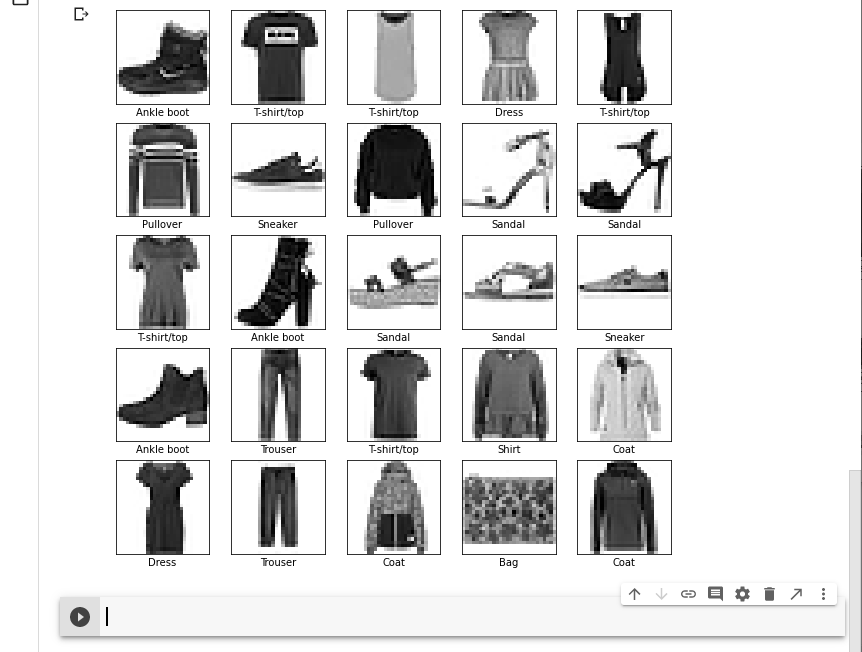
훈련 세트에서 처음 25개 이미지와 그 아래 클래스 이름을 출력해 보겠습니다.

4. 데이터 전처리 하기
신경망 모델에 입력하기 전에 이 값의 범위를 0~1 사이로 조정하겠습니다.
이렇게 하려면 255로 나누어야 합니다.
훈련 세트와 테스트 세트를 동일한 방식으로 전처리하는 것이 중요합니다

0~255인 픽셀 범위에 맞춰서 값의 범위를 0~1로 조정하기 위해 나눈다.
5. 모델 구성
신경망 모델을 만들려면 모델의 층을 구성한 다음 모델을 컴파일합니다.
신경망의 기본 구성 요소는 층(layer)입니다.
층은 입력된 데이터에서 표현을 추출합니다.
아마도 문제를 해결하는데 더 의미있는 표현이 추출될 것입니다.
대부분 딥러닝은 간단한 층을 연결하여 구성됩니다.
tf.keras.layers.Dense와 같은 층들의 가중치(parameter)는 훈련하는 동안 학습됩니다.

이모델의 첫 번째 층인 tf.keras.layers.Flatten은 2차원 배열(28 x 28 픽셀)의 이미지 포맷을 28 * 28 = 784 픽셀의 1차원 배열로 변환합니다.
이 층은 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘립니다.
이 층에는 학습되는 가중치가 없고 데이터를 변환하기만 합니다.
픽셀을 펼친 후에는 두 개의 tf.keras.layers.Dense 층이 연속되어 연결됩니다.
이 층을 밀집 연결(densely-connected) 또는 완전 연결(fully-connected) 층이라고 부릅니다.
첫 번째 Dense 층은 256개의 노드(또는 뉴런)를 가집니다.
두 번째 (마지막) 층은 10개의 노드의 소프트맥스(softmax) 층입니다.
이 층은 10개의 확률을 반환하고 반환된 값의 전체 합은 1입니다.
각 노드는 현재 이미지가 10개 클래스 중 하나에 속할 확률을 출력합니다.
6. 모델 컴파일
모델을 훈련하기 전에 필요한 몇 가지 설정이 모델 컴파일 단계에서 추가됩니다:
손실 함수(Loss function) : 훈련 하는 동안 모델의 오차를 측정합니다.
모델의 학습이 올바른 방향으로 향하도록 이 함수를 최소화해야 합니다.
옵티마이저(Optimizer) : 데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정합니다.
지표(Metrics) : 훈련 단계와 테스트 단계를 모니터링하기 위해 사용합니다.
다음 예에서는 올바르게 분류된 이미지의 비율인 정확도를 사용합니다.

sgd는 gradient를 구하는데 1개 데이터만 사용하게 된다.
7. 모델 훈련
훈련을 시작하기 위해 model.fit 메서드를 호출하면 모델이 훈련 데이터를 학습합니다
GPU를 사용하지 않을 경우, 반복횟수가 많을 수록 시간이 오래걸린다.
epochs=5는 5회 반복한다는 의미 이다.
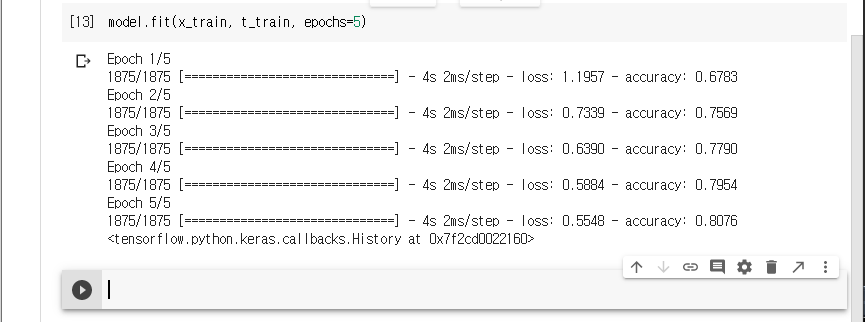
모델이 훈련되면서 손실과 정확도 지표가 출력됩니다.
8. 정확도 평가
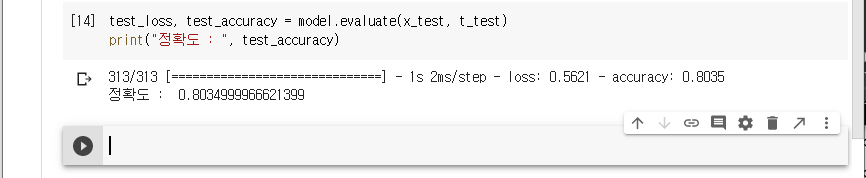
이 모델은 훈련 세트에서 약 0.80(80%) 정도의 정확도를 달성합니다.
10회 반복으로 수정하고 다시 정확도를 구해보자.
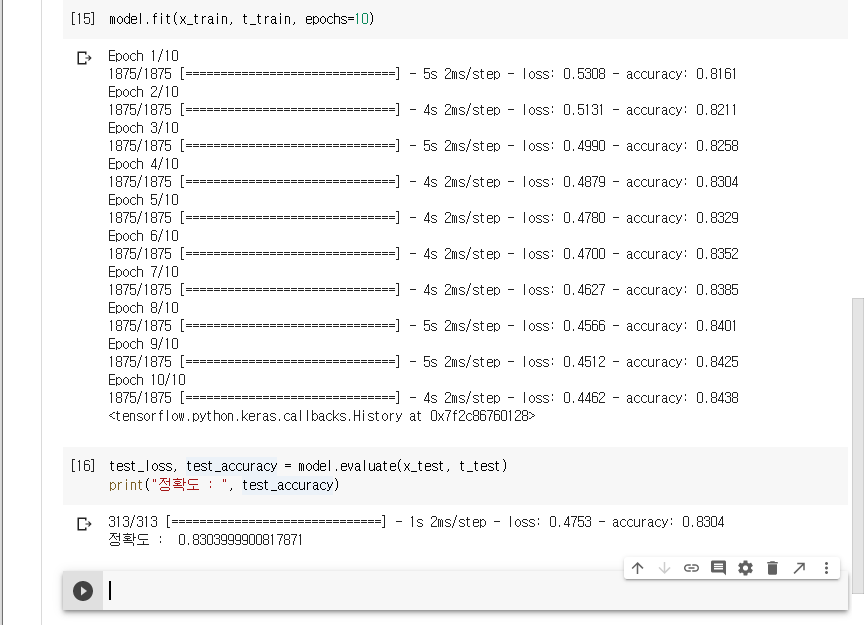
정확도가 83%정도 상승한 것을 확인할 수 있다.
테스트 세트의 정확도가 훈련 세트의 정확도보다 조금 낮습니다.
훈련 세트의 정확도와 테스트 세트의 정확도 사이의 차이는 과대적합(overfitting) 때문입니다.
과대적합은 머신러닝 모델이 훈련 데이터보다 새로운 데이터에서 성능이 낮아지는 현상을 말합니다.
9. 예측 만들기
훈련된 모델을 사용하여 이미지에 대한 예측을 만들 수 있습니다.
테스트 세트에 있는 각 이미지의 레이블을 예측하고, 첫 번째 예측을 확인해 본다.
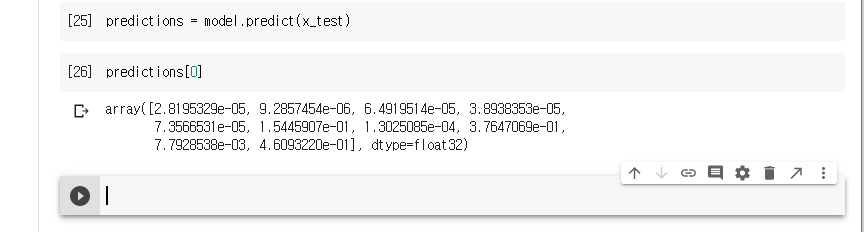
이 예측은 10개의 숫자 배열로 나타납니다.
이 값은 10개의 패션 품목에 상응하는 모델의 신뢰도(confidence)를 나타냅니다.
가장 높은 신뢰도를 가진 레이블을 찾아본다.
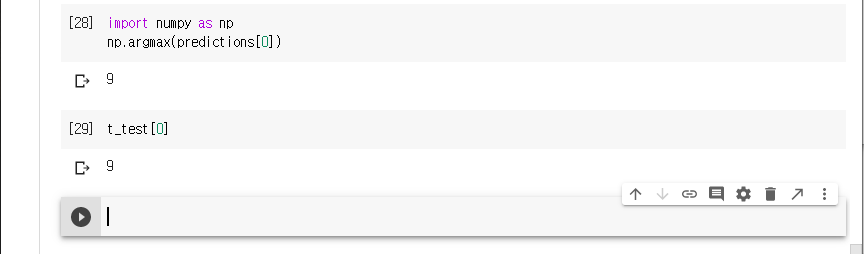
모델은 이 이미지가 앵클 부츠(class_name[9])라고 가장 확신하고 있습니다.
이 값이 맞는지 테스트 레이블을 확인해 본다.