7. 타이타닉 생존자 예측하기
페이지 정보
작성자 관리자 댓글 0건 조회 3,587회 작성일 20-07-29 20:27본문
7. 타이타닉 생존자 예측하기
1. Kaggle 소개
2010년에 설립된 예측모델 및 분석 플랫폼이다.
2017년 3월에 구글에 인수됨
여기에는 방대한 데이터셋들이 있읍니다.
그 데이터 셋을 이용하여 다양한 경연에 참여하여 분석할 수 있다.
Competitions 메뉴를 보면 다양한 경연이 보인다.
2. 타이타닉 데이터셋 다운받기
Titanic을 검색하여 들어간다.
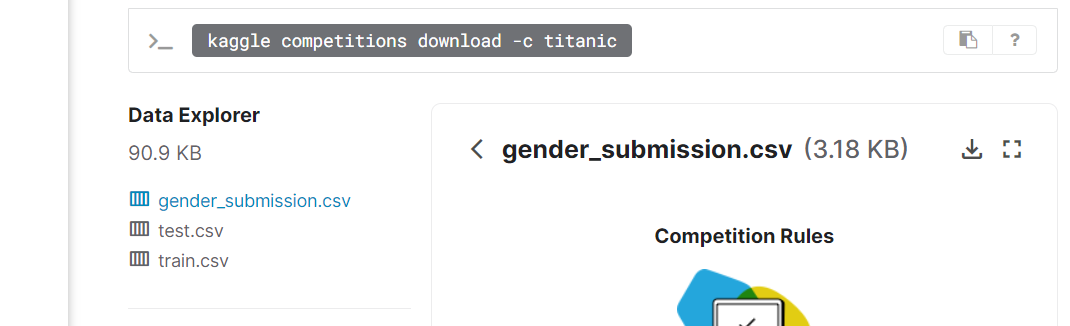
- training set과 test set을 다운받는다.
Notebooks 메뉴을 보면 다른 회원들이 타이타닉 데이터 셋을 이용하여 생존자를 예측한 결과를 볼 수 있다.
3. colab에서 분석하기
- 데이터셋 불러오기
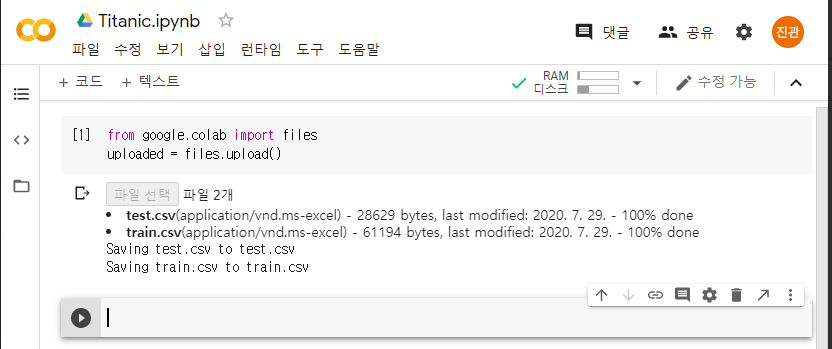
다운받은 파일을 같이 선택하면 2개파일을 불러올 수 있다.
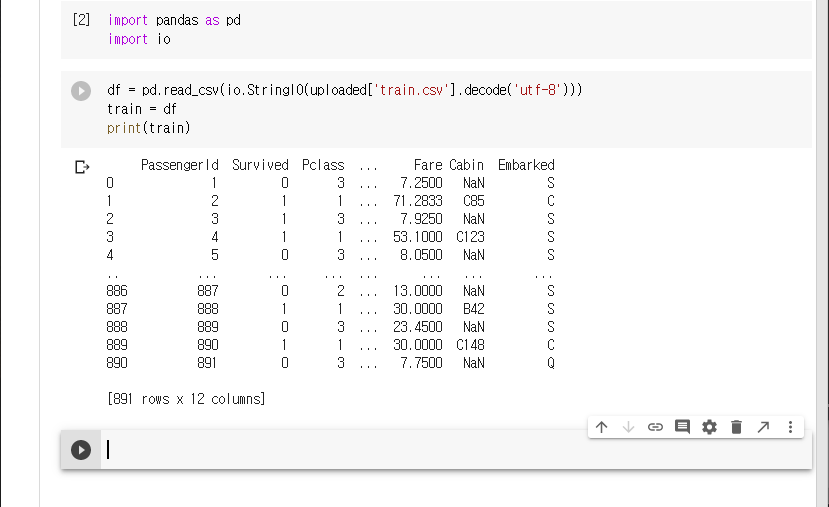
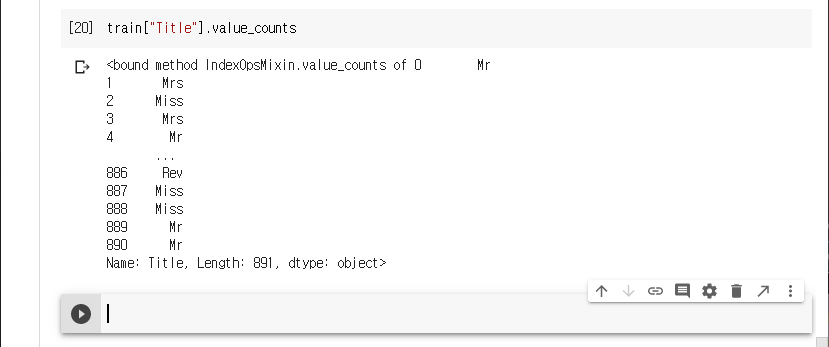
train set을 불러와 데이터프레임으로 만든다.
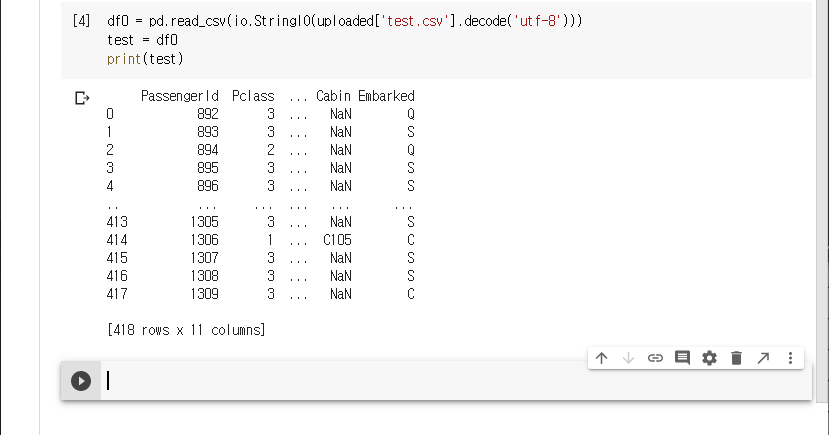
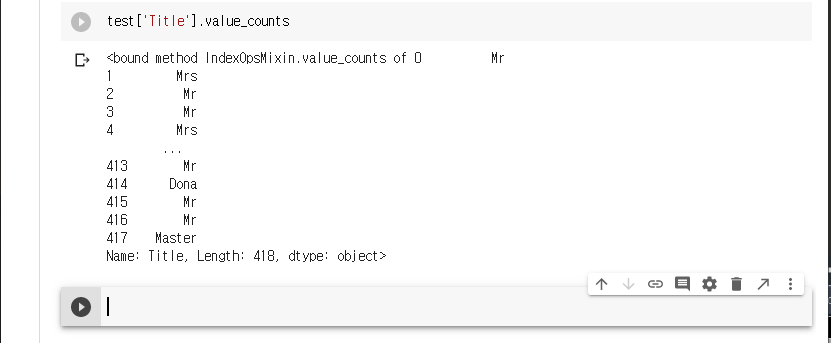
test set를 불러와 데이타프레임으로 변환한다.
train set의 정보를 확인한다.
test set의 정보를 확인한다.
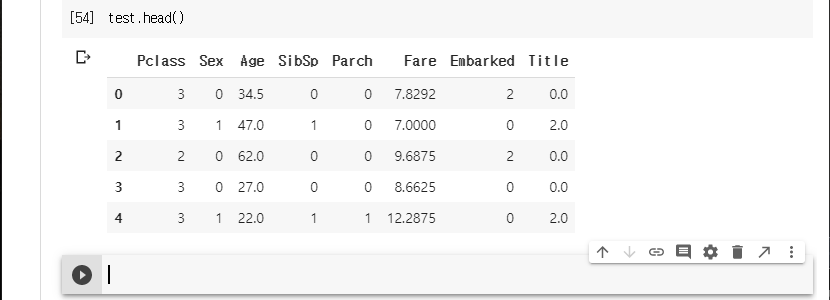
head()함수는 앞쪽 5개의 데이터만 볼 수 있다.
데이터 중 NAN 결측값으로 전처리를 통해 해결해야 한다.
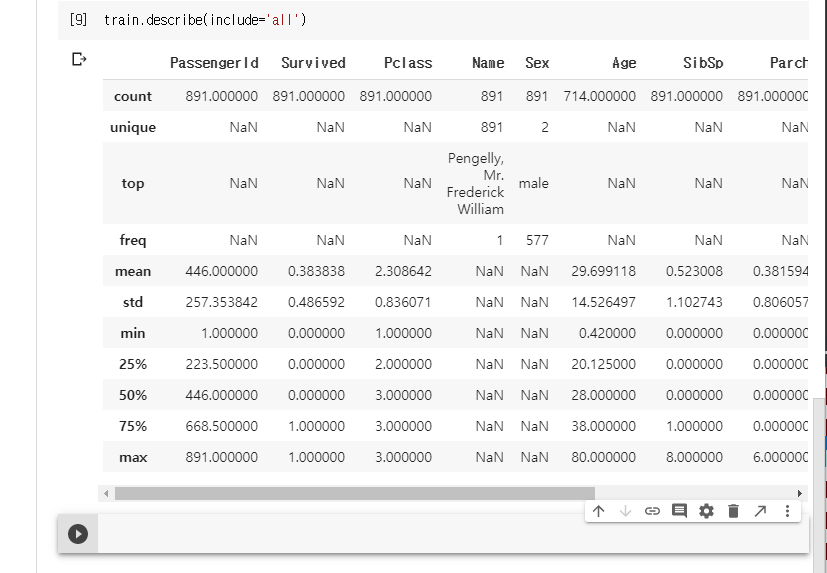

데이터셋의 Feature를 확인한다.
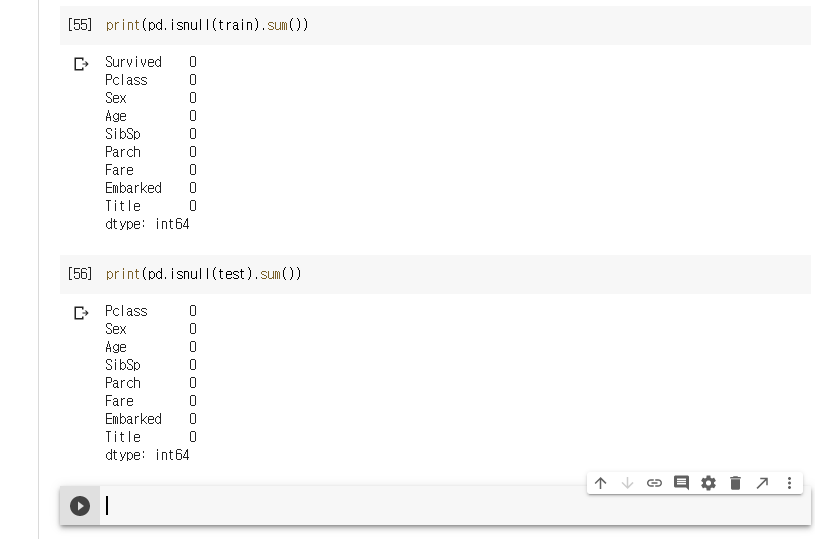
데이터셋에 NaN 값이 얼마나 존재하는지 확인해 본다.
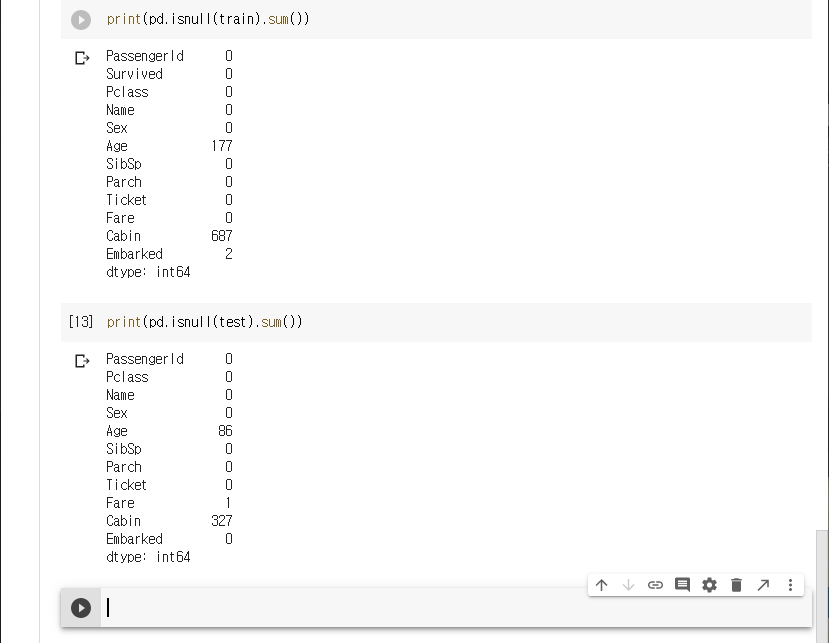
예측 정확도를 높이기 위해서는 이 NaN 값을 적절히 전처리를 통해 없애 주어야 한다.

그래프를 그리는 pivot() 함수를 만든다.
성별(sex)에 따른 생존률을 그래프로 그린다.
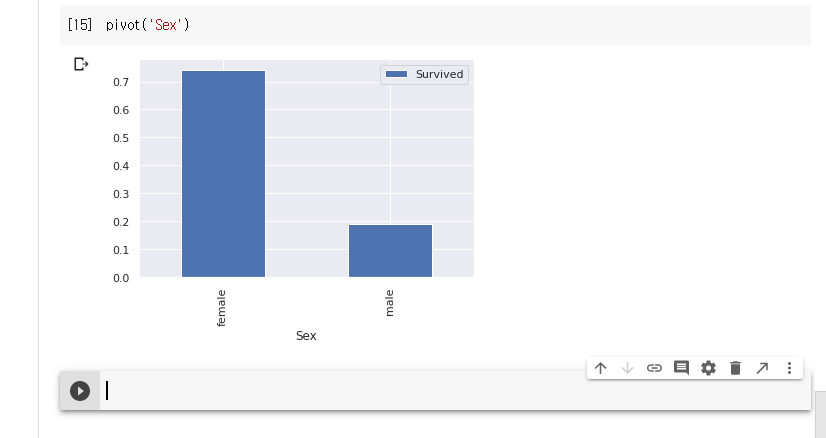
남성보다 여성이 생존률이 높게 나타난것을 볼 수 있다.
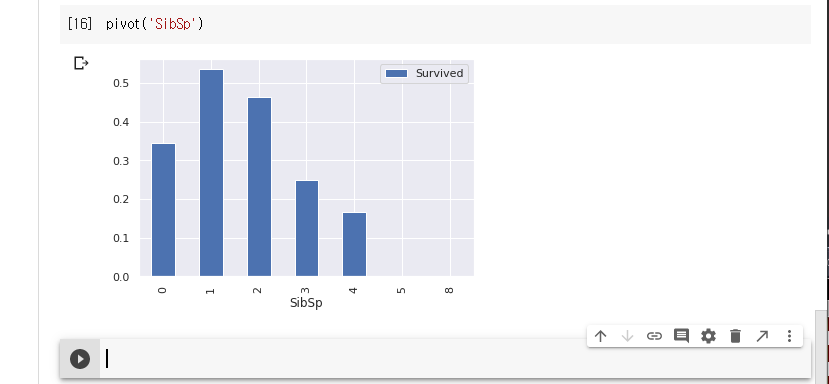
가족수에 따른 생존률입니다.
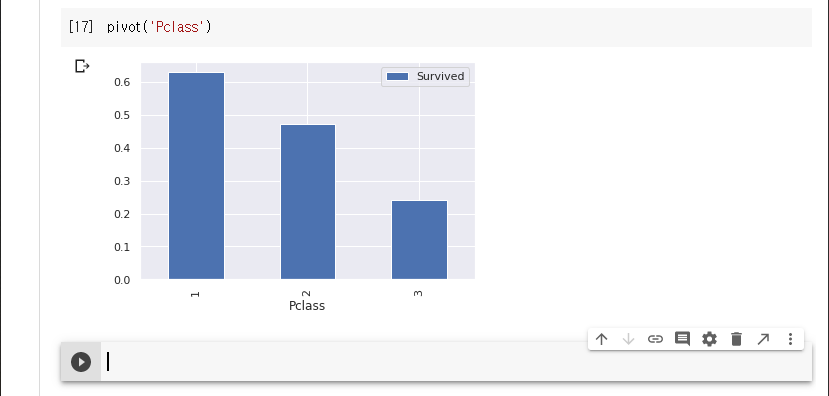
좌석 등급에 따른 생존률입니다.
4. 전처리 하기
Name를 그대로 머신러닝 모델에 적용하면 않됩니다.
이름은 종류가 많기 때문에 생존률를 구하기 힘들므로, 이름에서 성별을 유추할 수 있는 단어들을 뽑아 확인하도록 전처리 해보겠습니다.
train, test set를 합친다.

Name 에서 성별 확인 가능한 단어를 추출하는 반복문입니다.
머신러닝에 사용할 수 있도록 numbering을 한다.

성별 요인들을 0 ~ 3까지로 매핑 시킨다.
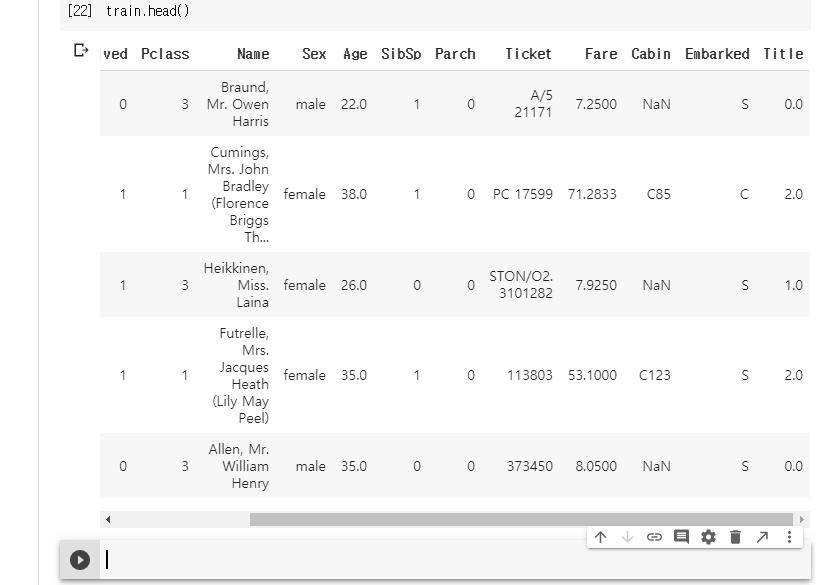
train 데이터를 보면 끝쪽에 추가된 것을 확인할 수 있다.
전처리후, Title에 결측치가 존재하는를 확인한다.
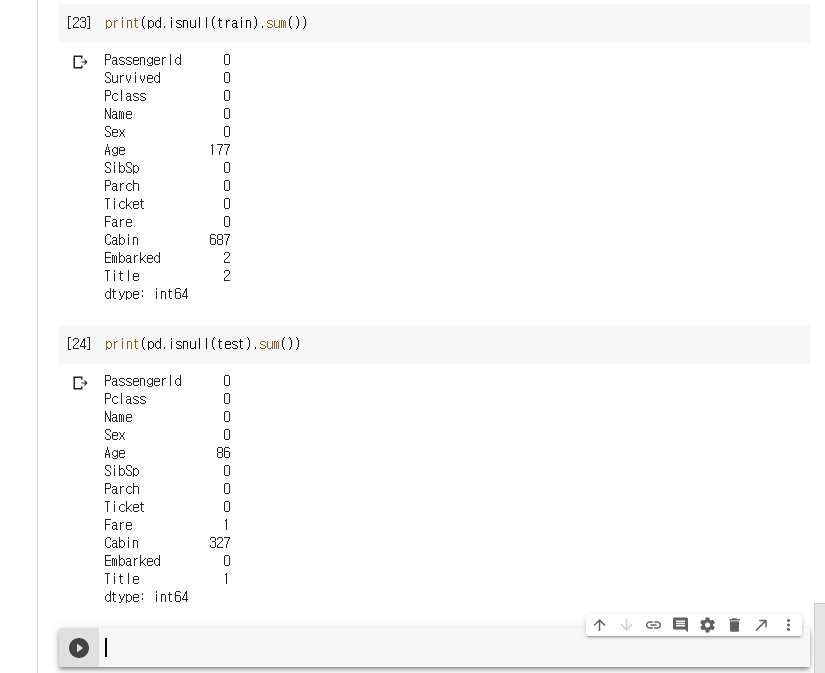
아직도 train에 2개 test에 1개가 남았있다. 이것도 해결하면 좋겠으나, 갯수가 작으므로 평균값으로 대체하도록하겠습니다.

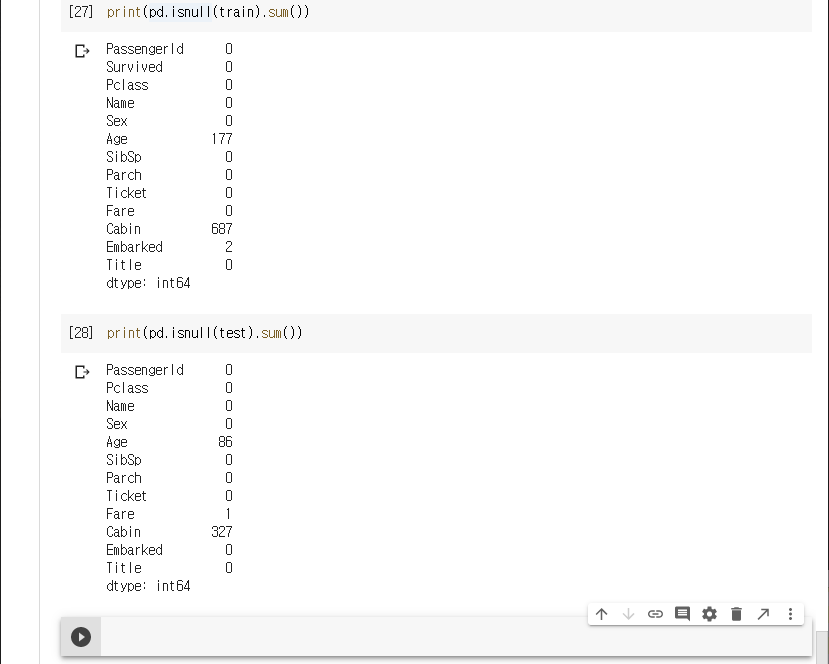
다시 결측값이 없어졌는지를 확인한다.
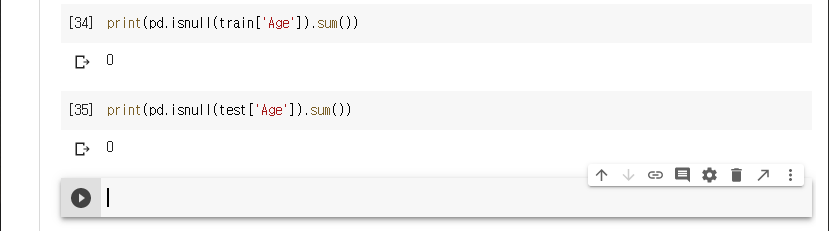
나이(Age)는 결측치를 중위값으로 대체한다.

다시 결과를 확인한다.
train['Embarked']에 2개의 결측치가 존재한다. 이것을 처리해보록하겠습니다.
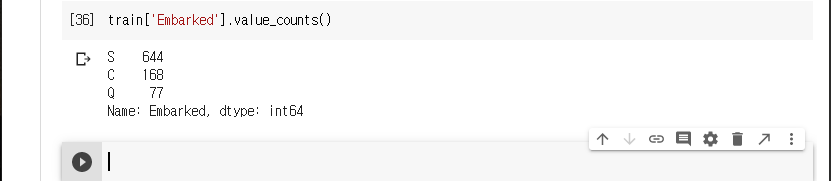
train['Embarked']는 2개의 결측값이 있다. 이것은 S값이 가장 많기 때문에 S로 대체한다.

S, C, Q 값을 0, 1, 2로 맵핑한다.
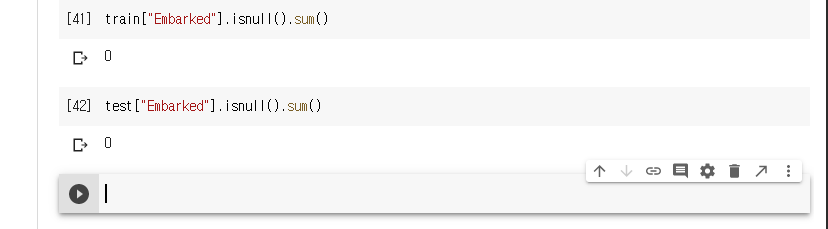
결측값이 없어졌는지 확인한다.
Fare는 결측값이 1개 존재한다. 이것은 평균값으로 대체하도록 한다.
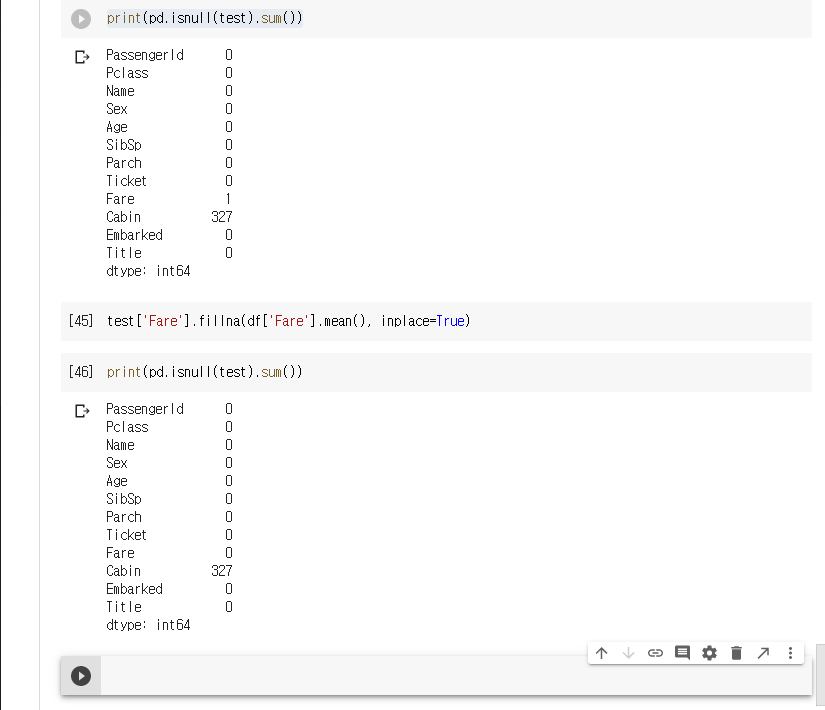
Cabin, Ticket, PassengerId는 삭제한다.
결과를 확인한다.
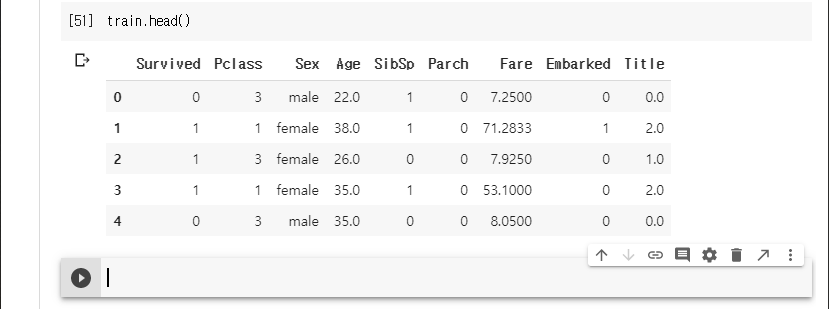
성별이 아직 맵핑이 되지 않았다. 이것도 처리한다.
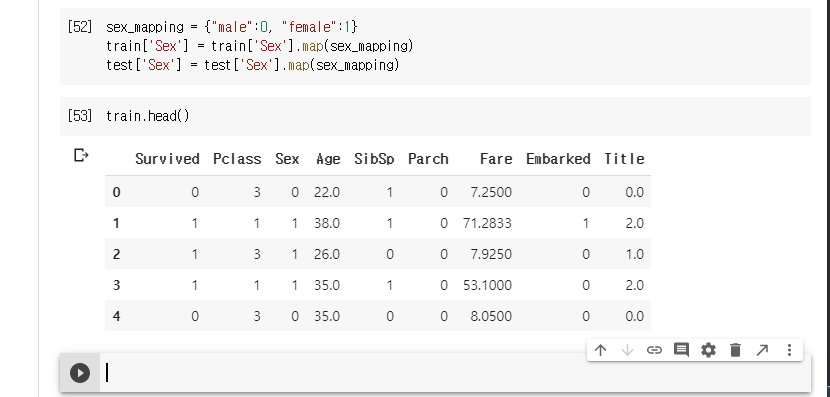
결측값이 있는다 다시 한번 확인한다.
5. 생존율 예측하기
예측해야 할 것이 survived 이기 때문에 따로 떼어서 예측해보록 한다.
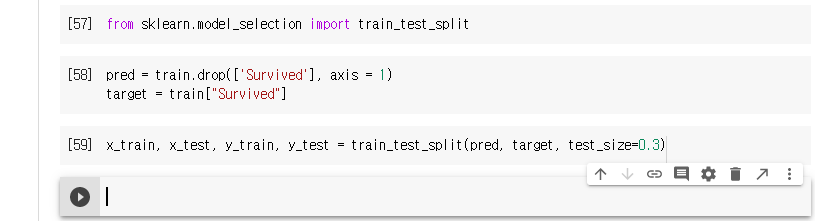
학습용 데이터를 분리한다.
로지스틱 회귀 모델을 사용하여 예측해보록 한다.
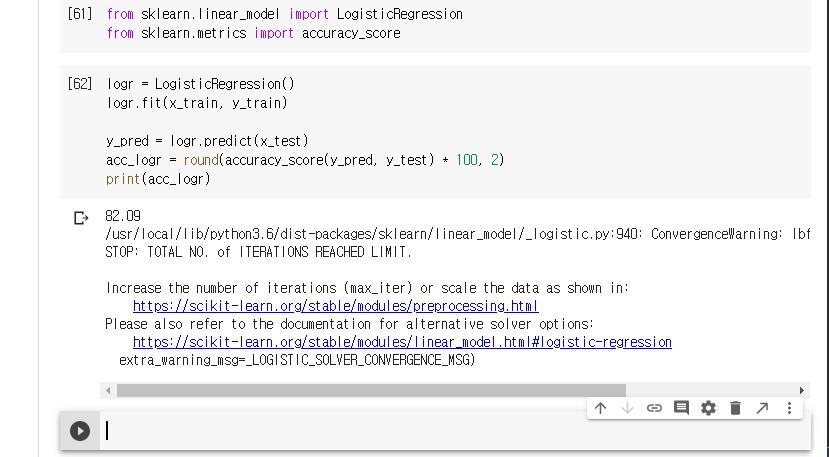
로지스틱 회귀는 82.09가 나왔다.
결정트리 모델을 통해 예측해보겠습니다.
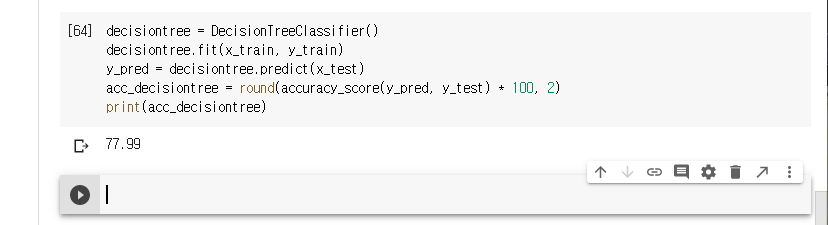
77.99의 결과가 나타납니다.
랜덤 포레스트 모델을 사용하여 예측해보겠습니다.
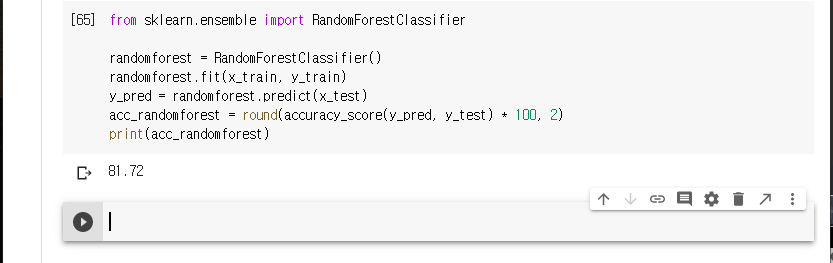
81.72 의 결과가 나타납니다.
KNN 모델을 사용하여 예측해보겠습니다.
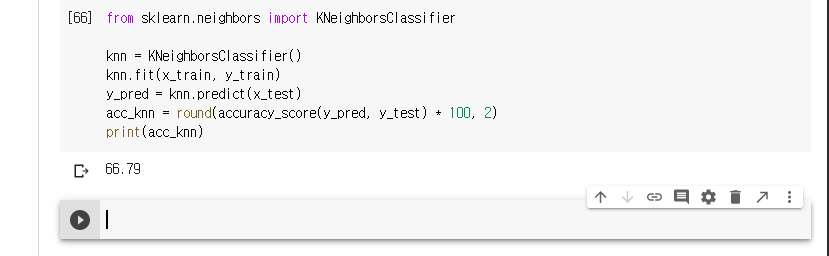
66.79가 나타납니다.
로지스틱 회귀가 가장 높게 나타났습니다.
결과를 정리해보록 하겠습니다.
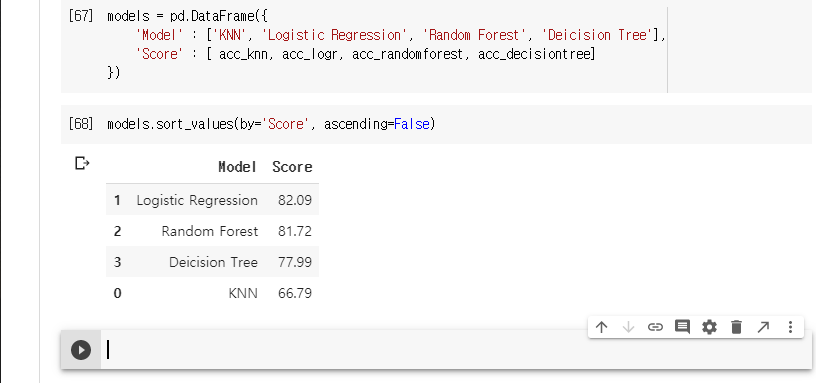
생존자 예측 결과 82%가 나왔는데, 케글에서는 더높은 예측 결과를 볼 수 있다.
전처리를 더 세밀하게 하면 정밀한 예측 결과를 얻을 것이다.