14. Support Vector Regression (SVR)
페이지 정보
작성자 관리자 댓글 0건 조회 4,642회 작성일 20-03-09 21:45본문
14. Support Vector Regression (SVR)
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVR.html
https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVR.html#sklearn.svm.LinearSVR
SVM 알고리즘은 다목적으로 사용할 수 있다.
선형, 비선형 분류 뿐만아니라, 선형, 비선형 회귀에도 사용할 수 있다.
회귀에 적용하는 방법은 목표를 반대로 하는 것이다.
일정한 마진 오류 안에서, 두 클래스 간의 도로 폭이 가능한 한 최대가 되도록 하는 대신,
SVM 회귀는 제한된 마진 오류( 즉, 도로 밖의 샘플) 안에서 도로 안에 가능한 한 많은 샘플이 들어가도록 학습한다.
도록의 폭은 epsilon 하이퍼파라미터로 조절한다.
다음은 무작위로 선형 데이터 셋을 생성하고, 훈련시킨 두개의 SVM 선형 회귀 모델이다.
하나는 마진을 크게(epsilon = 1.5), 다른 하나는 마진을 작게 (epsilon = 0.5)하여 만들었다.
실습.
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.svm import LinearSVR
import matplotlib.pyplot as plt
# 가우시안 분포를 따르는 데이터 셋을 만든다.
np.random.seed(42)
m = 50
X = 2 * np.random.rand(m, 1)
y = (4 + 3 * X + np.random.randn(m,1)).ravel()
print("----------------\n X")
print(X)
print("----------------\n y")
print(y)
# 서포트 벡터 정하기 : 마진이 큰 모형(epsilon=1.5,)
svm_reg = LinearSVR(epsilon=1.5, random_state=42)
svm_reg.fit(X,y)
# X로 예측한 값 = y_pred
y_pred =svm_reg.predict(X)
print("----------------\n y_pred")
print(y_pred)
# off_margin = 실제 y값과 예측값 사이의 오차를 절대값으로 표현하되,
# 해당 모형의 epsilon보다 크거나 같은 값
off_margin = (np.abs(y - y_pred) >= svm_reg.epsilon)
print("----------------\n off_margin")
print(off_margin)
# np.argwhere는 행렬에서 True에 해당하는 값 위치를 반환한다.
# 오차가 epsilon보다 큰 값들의 위치를 반환하며 이 것들이 곧 서포트 벡터로 활용된다.
svm_reg.support_ = np.argwhere(off_margin)
print("----------------\n svm_reg.support_")
print(svm_reg.support_)
# np.linspace로 axes의 첫번째 값과 두번째 값 사이를 100개로 쪼갠 일정한 값
# 생성 후, 100행 1열로 reshape 한다.
axes = [0,2,3,11]
x1s = np.linspace(axes[0], axes[1], 100).reshape(100,1)
y_pred = svm_reg.predict(x1s)
# plot 찍기
# x, y를 plot하고, y_pred에서 epsilon을 빼고 더한 값도 plot 한다.
# 아까 구햇던 서포트 백터를 scatter 찍기
plt.figure(figsize = (9,4))
#plt.subplot(121)
plt.plot(x1s, y_pred, 'k-', linewidth=2, label=r'y1')
plt.plot(x1s, y_pred + svm_reg.epsilon, 'k--')
plt.plot(x1s, y_pred - svm_reg.epsilon, 'k--')
plt.scatter(X[svm_reg.support_], y[svm_reg.support_], s = 180, facecolors='#FFAAAA')
plt.plot(X, y, 'bo')
plt.xlabel('x1', fontsize=18)
plt.legend(loc='upper left', fontsize=18)
plt.axis(axes)
plt.title(r'ε={}'.format(svm_reg.epsilon), fontsize=18)
plt.ylabel('y', fontsize=18, rotation=0)
eps_x1 = 1
eps_y_pred=svm_reg.predict([[eps_x1]])
#plt.plot([eps_x1, eps_x1], [eps_y_pred, eps_y_pred - svm_reg.epsilon], 'k-', linewidth=2)
# eps_x1=1로 두고, 예측한 값 = eps_y_pred
# 화살표와 함께 text를 넘기는 annotate
# epsilon : 도로의 폭을 나타낸다.
# xy는 주석을 달 위치이다. ( eps_x1, eps_y_pred )
# xytext 는 xy위치에 넣을 text
# textcoords는 지금 넣은 'data'가 default값이며, 주석을 달 객체의 좌표 값 사용을 뜻한다.
# arrowprops는 화살표 설정
plt.annotate(
'', xy=(eps_x1, eps_y_pred), xycoords='data',
xytext=(eps_x1, eps_y_pred - svm_reg.epsilon),
textcoords='data', arrowprops={'arrowstyle':'<->', 'linewidth':1.5}
)
plt.text(0.91, 5.6, r'ε', fontsize=20)
plt.show()
결과.
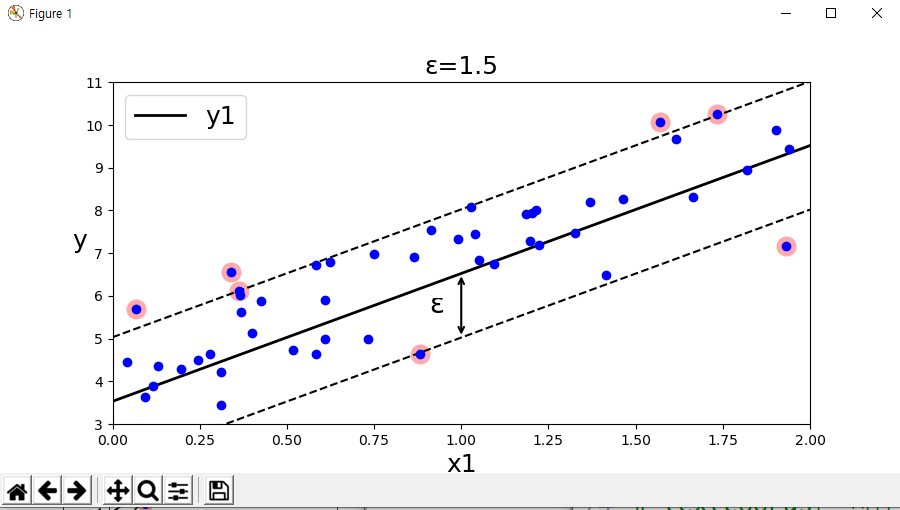
마진을 0.5로 수정후 실행하였다.
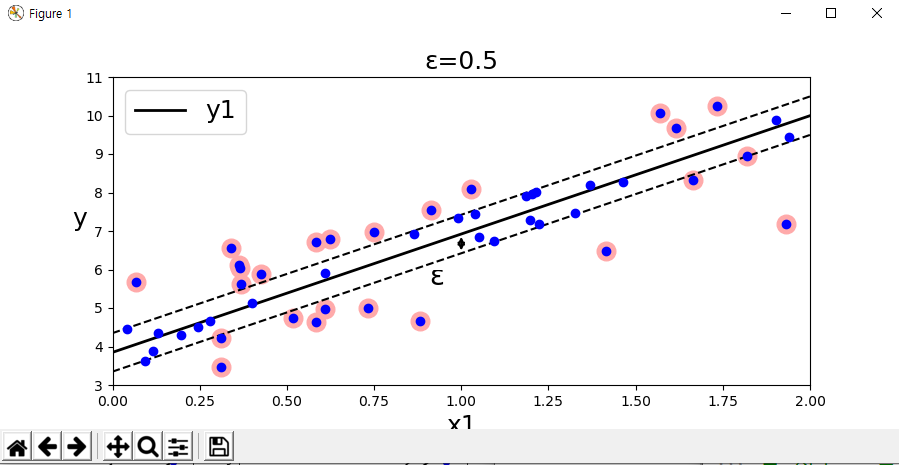
위의 그래프를 보면, 마진 안에서는 훈련 샘플이 추가되어도 모델의 예측에는 영향이 없는 것을 알 수 있다.
따라서 이 모델을 epsilon에 민감하지 않다고 말한다.
허용오차와는 다르다.
SVM 회귀모델인 SVR와 LinearSVR에서 허용오차는 tol 매개변수, 도로의 폭은 epsilon 매개변수를 지정한다.
tol 매개변수의 기본값은 SVC, LinearSVC와 마찬가지로 각각 0.001, 0.0001이다.
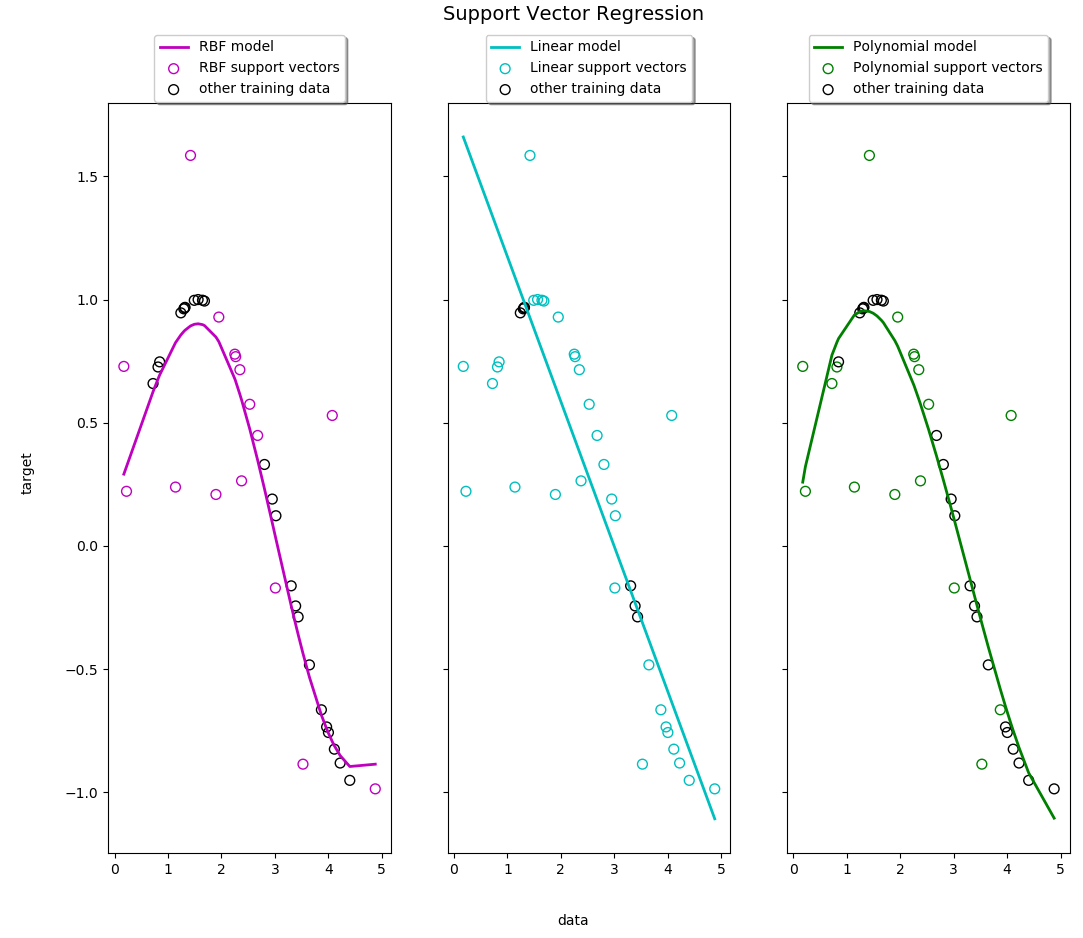
비선형 회귀 작업을 처리해 보겠습니다.
다음은 선형, 다항식 및 RBF 커널을 사용한 1D 회귀 분석의 예이다.
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.svm import SVR
import matplotlib.pyplot as plt
# #############################################################################
# Generate sample data
X = np.sort(5 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel()
print("----------------\n X")
print(X)
print("----------------\n y")
print(y)
# Add noise to targets
y[::5] += 3 * (0.5 - np.random.rand(8))
print("----------------\n y")
print(y)
# Fit regression model
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
svr_lin = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1,
coef0=1)
# Look at the results
lw = 2
svrs = [svr_rbf, svr_lin, svr_poly]
kernel_label = ['RBF', 'Linear', 'Polynomial']
model_color = ['m', 'c', 'g']
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15, 10), sharey=True)
for ix, svr in enumerate(svrs):
axes[ix].plot(X, svr.fit(X, y).predict(X), color=model_color[ix], lw=lw,
label='{} model'.format(kernel_label[ix]))
axes[ix].scatter(X[svr.support_], y[svr.support_], facecolor="none",
edgecolor=model_color[ix], s=50,
label='{} support vectors'.format(kernel_label[ix]))
axes[ix].scatter(X[np.setdiff1d(np.arange(len(X)), svr.support_)],
y[np.setdiff1d(np.arange(len(X)), svr.support_)],
facecolor="none", edgecolor="k", s=50,
label='other training data')
axes[ix].legend(loc='upper center', bbox_to_anchor=(0.5, 1.1),
ncol=1, fancybox=True, shadow=True)
fig.text(0.5, 0.04, 'data', ha='center', va='center')
fig.text(0.06, 0.5, 'target', ha='center', va='center', rotation='vertical')
fig.suptitle("Support Vector Regression", fontsize=14)
plt.show()
참고.
https://scikit-learn.org/stable/auto_examples/svm/plot_svm_regression.html