12. 서포트 벡터 머신
페이지 정보
작성자 관리자 댓글 0건 조회 4,434회 작성일 20-03-09 13:09본문
12. 서포트 벡터 머신
퍼셉트론은 가장 단순하고 빠른 판별 함수 기반 분류 모형이지만 판별 경계선(decision hyperplane)이 유니크하게 존재하지 않는다는 특징이 있다. 서포트 벡터 머신(SVM: support vector machine)은 퍼셉트론 기반의 모형에 가장 안정적인 판별 경계선을 찾기 위한 제한 조건을 추가한 모형이라고 볼 수 있다.
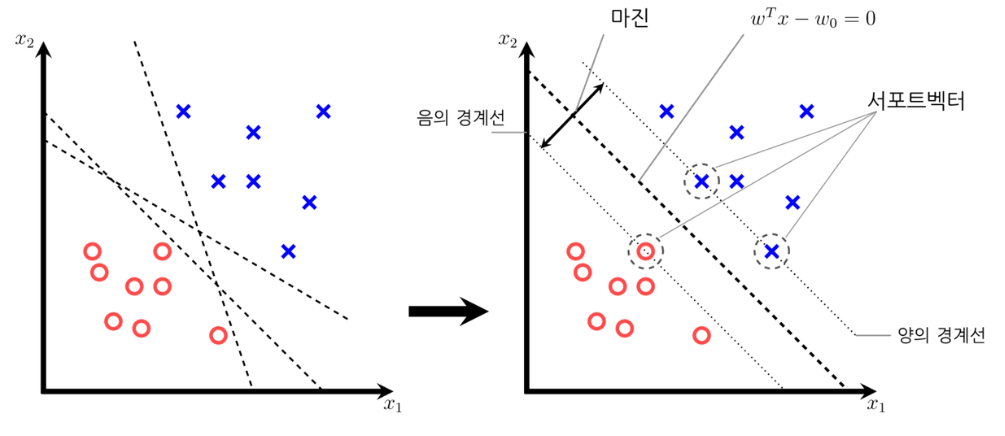
서포트와 마진
다음과 같이 N개의 학습용 데이터가 있다고 하자.
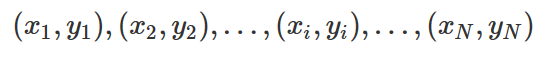
판별함수모형에서 y는 +1, −1 두 개의 값을 가진다
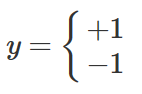
x 데이터 중에서 y값이 +1인 데이터를 x+ , y값이 -1인 데이터를 x− 라고 하자.
판별함수 모형에서 직선인 판별 함수 f(x)는 다음과 같은 수식으로 나타낼 수 있다.
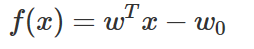
판별함수의 정의에 따라 y값이 +1인 그 데이터 x+에 대한 판별함수 값은 양수가 된다.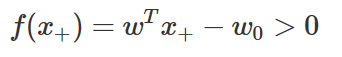
반대로 y값이 −1인 그 데이터 x−에 대한 판별함수 값은 음수가 된다.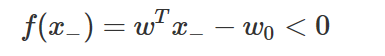
y값이 +1인 데이터 중에서 판별 함수의 값이 가장 작은 데이터를 x+라고 하고 y값이 −1인 데이터 중에서 판별함수의 값이 가장 큰 데이터를 x−라고 하자.
이 데이터들은 각각의 클래스에 속한 데이터 중에서 가장 경계선에 가까이 붙어있는 최전방(most front)의 데이터들이다.
이러한 데이터를 서포트(support) 혹은 서포트 벡터(support vector)라고 한다. 물론 이 서포트에 대해서도 부호 조건은 만족되어야 한다.
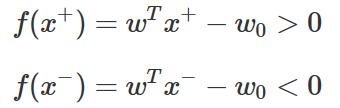
서포트에 대한 판별 함수의 값 f(x+), f(x−)값은 부호 조건만 지키면 어떤 값이 되어도 괜찮다.
따라서 다음과 같은 조건을 만족하도록 판별 함수를 구한다.
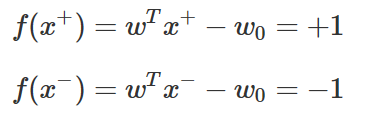
다음 그림은 서포트벡터의 판별함수 값을 나타낸다.
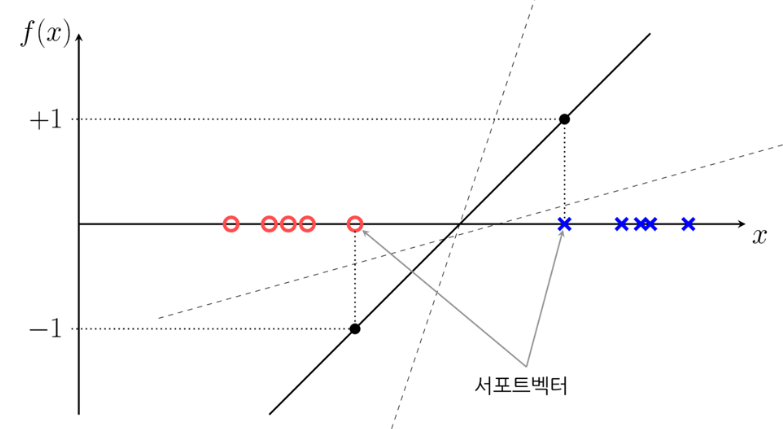
이렇게 되면 모든 x+, x+ 데이터에 대해 판별함수의 값의 절대값이 1보다 커지므로 다음 부등식이 성립한다.
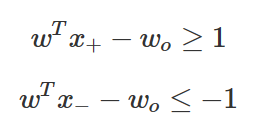
판별 경계선 wTx−w0=0과 점 x+, x− 사이의 거리는 다음과 같이 계산할 수 있다.
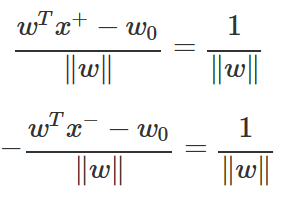
이 거리의 합을 마진(margin)이라고 하며 마진값이 클 수록 더 경계선이 안정적이라고 볼 수 있다. 그런데 위에서 정한 스케일링에 의해 마진은 다음과 같이 정리된다.
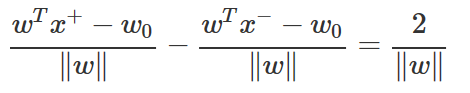
마진 값이 최대가 되는 경우는 ‖w‖ 즉, ‖w‖2 가 최소가 되는 경우와 같다.
즉 다음과 같은 목적함수를 최소화하면 된다.
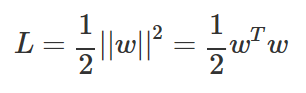
또한 모든 표본 데이터에 대해 분류는 제대로 되어야 하므로 모든 데이터 xi,yi(i=1,…,N)에 대해 다음 조건을 만족해야 한다. 위에서 스케일링을 사용하여 모든 데이터에 대해 f(xi)=wTxi−wo 가 1보다 크거나 -1보다 작게 만들었다는 점을 이용한다.
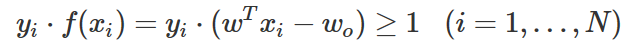
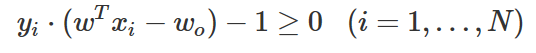
라그랑주 승수법을 사용하면 최소화 목적함수를 다음과 같이 고치면 된다.
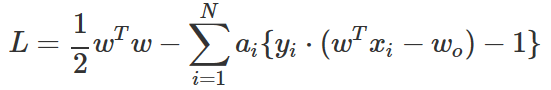
여기에서 ai은 각각의 부등식에 대한 라그랑주 승수이다.
이 최적화 문제를 풀어 w, w0, a를 구하면 판별함수를 얻을 수 있다.
KKT(Karush–Kuhn–Tucker) 조건에 따르면 부등식 제한 조건이 있는 경우에는 등식 제한조건을 가지는 라그랑주 승수 방법과 비슷하지만 i번째 부등식이 있으나 없으나 답이 같은 경우에는 라그랑지 승수의 값이 ai=0이 된다.
이 경우는 판별함수의 값 wTxi−wo 이 −1보다 작거나 1보다 큰 경우이다.
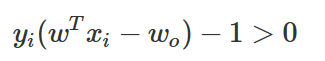
학습 데이터 중에서 최전방 데이터인 서포트 벡터가 아닌 모든 데이터들에 대해서는 이 조건이 만족되므로 서포트 벡터가 아닌 데이터는 라그랑지 승수가 0이라는 것을 알 수 있다.
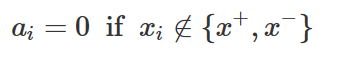
듀얼 형식
최적화 조건은 목적함수 L을 w, w0로 미분한 값이 0이 되어야 하는 것이다.
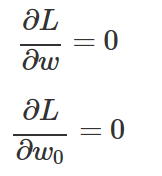
이 식을 풀어서 정리하면 다음과 같아진다.
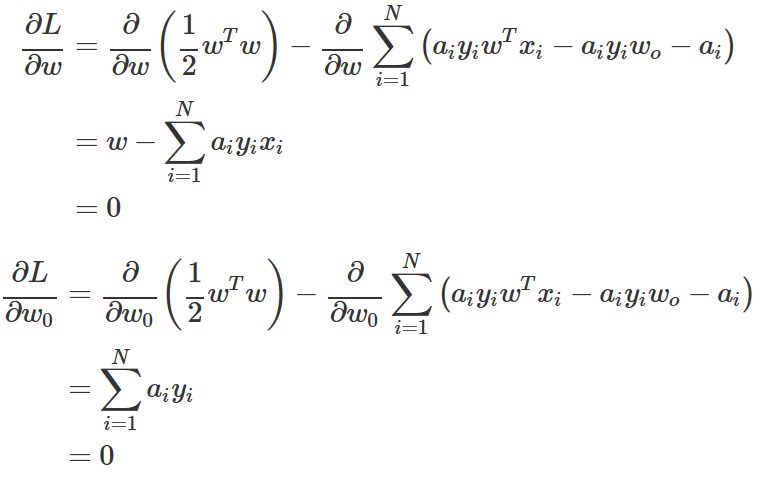
즉,
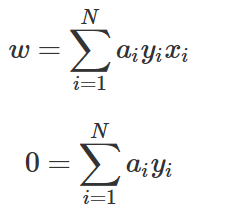
이 두 수식을 원래의 목적함수에 대입하여 w, w0 을 없애면 다음과 같다.
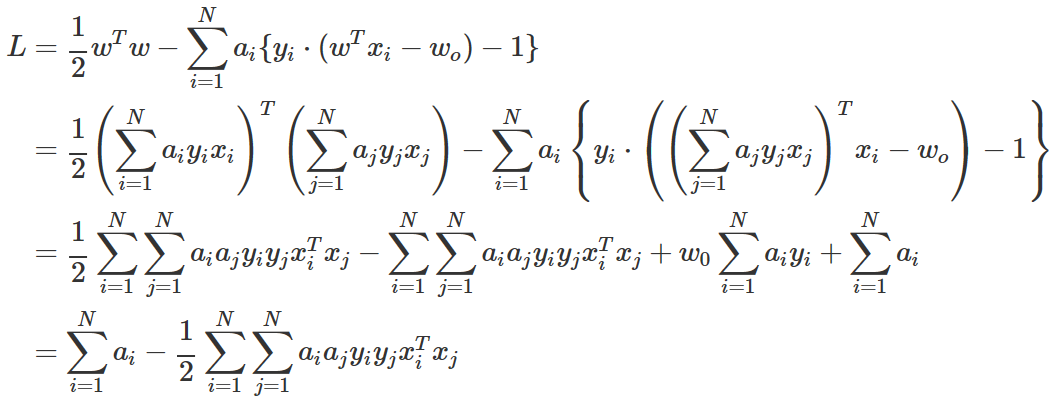
즉,
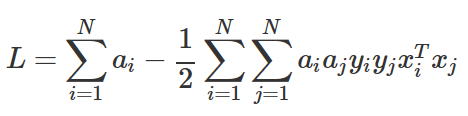
이 때 a는 다음 조건을 만족한다.
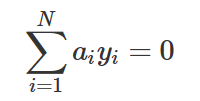
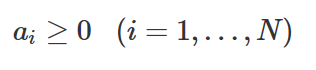
이 문제는 w를 구하는 문제가 아니라 a만을 구하는 문제로 바뀌었으므로 듀얼형식(dual form)이라고 한다. 듀얼형식으로 바꾸면 수치적으로 박스(Box)제한 조건이 있는 이차프로그래밍(QP; quadratic programming) 문제가 되므로 원래의 문제보다는 효율적으로 풀 수 있다.
듀얼형식 문제를 풀어 함수 L를 최소화하는 a를 구하면 예측 모형을 다음과 같이 쓸 수 있다.
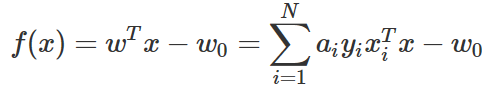
w0는
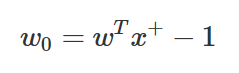
또는
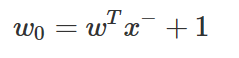
또는
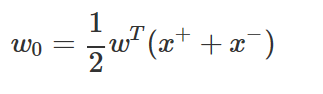
로 구한다.
라그랑주 승수 값이 0 즉, ai=0이면 해당 데이터는 예측 모형, 즉 w계산에 아무런 기여를 하지 않으므로 위 식을 실제로는 다음과 같다.
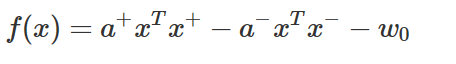
여기에서 xTx+는 x와 x+사이의 (코사인)유사도, xTx−는 x와 x−사이의 (코사인)유사도이므로 결국 두 서포트 벡터와의 유사도를 측정해서 값이 큰 쪽으로 판별하게 된다.
Scikit-Learn의 서포트 벡터 머신
Scikit-Learn의 svm 서브페키지는 서포트 벡터 머신 모형인 SVC (Support Vector Classifier) 클래스를 제공한다.
실습.
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
path = 'C:\\Windows\\Fonts\\나눔고딕.ttf'
fontprop = fm.FontProperties(fname=path, size=18)
X, y = make_blobs(n_samples=50, centers=2, cluster_std=0.5, random_state=4)
y = 2 * y - 1
plt.scatter(X[y == -1, 0], X[y == -1, 1], marker='o', label="-1 class")
plt.scatter(X[y == +1, 0], X[y == +1, 1], marker='x', label="+1 class")
plt.xlabel("x1", fontproperties=fontprop)
plt.ylabel("x2", fontproperties=fontprop)
plt.legend()
plt.title("학습용 데이터", fontproperties=fontprop)
plt.show()
결과.
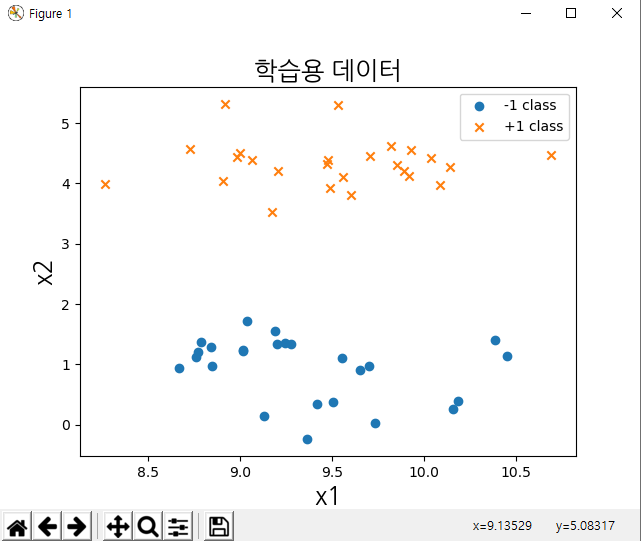
SVC 클래스는 커널(kernel)을 선택하는 인수 kernel과 슬랙변수 가중치(slack variable weight)를 선택하는 인수 C를 받는데 지금까지 공부한 서포트 벡터 머신을 사용하려면 인수를 다음처럼 넣어준다. 이 인수들에 대해서는 곧 설명한다.
SVC(kernel='linear', C=1e10)
SVC를 사용하여 모형을 구하면 다음과 같은 속성값을 가진다.
n_support_: 각 클래스의 서포트의 개수support_: 각 클래스의 서포트의 인덱스support_vectors_: 각 클래스의 서포트의 x 값. x+x+와 x−x−coef_: ww 벡터intercept_: −w0−w0dual_coef_: 각 원소가 ai⋅yiai⋅yi로 이루어진 벡터