5. 신경망(Neural Networks)
페이지 정보
작성자 관리자 댓글 0건 조회 3,715회 작성일 20-03-02 17:31본문
5. 신경망(Neural Networks)
신경망은 torch.nn 패키지를 사용하여 생성할 수 있습니다.
nn 은 모델을 정의하고 미분하는데 autograd 를 사용합니다.
nn.Module 은 계층(layer)과 output 을 반환하는 forward(input) 메서드를 포함하고 있습니다.
이는 피드-포워드 네트워크(Feed-forward network)입니다.
입력(input)을 받아 여러 계층에 차례로 전달한 후, 최종 출력(output)을 제공합니다.
신경망의 전형적인 학습 과정은 다음과 같습니다:
•학습 가능한 매개변수(또는 가중치(weight))를 갖는 신경망을 정의합니다.
•데이터셋(dataset) 입력을 반복합니다.
•입력을 신경망에서 처리합니다.
•손실(loss; 출력이 정답으로부터 얼마나 떨어져있는지)을 계산합니다.
•변화도(gradient)를 신경망의 매개변수들에 역으로 전파합니다.
•신경망의 가중치를 갱신합니다.
가중치(wiehgt) = 가중치(weight) - 학습율(learning rate) * 변화도(gradient)
신경망 정의하기
신경망을 정의합니다:
실습.
# -*- coding: utf-8 -*-
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
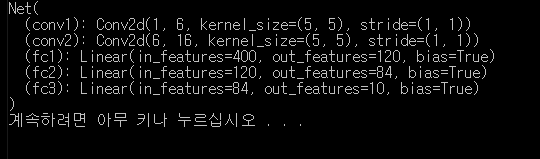
net = Net()
print(net)
결과.
forward 함수만 정의하게 되면, (변화도를 계산하는) backward 함수는 autograd 를 사용하여 자동으로 정의됩니다.
forward 함수에서는 어떠한 Tensor 연산을 사용해도 됩니다.
모델의 학습 가능한 매개변수들은 net.parameters() 에 의해 반환됩니다.
forward의 입력은 autograd.Variable 이고, 출력 또한 마찬가지입니다.
이 신경망(LeNet)의 입력은 32x32입니다.
이 신경망에 MNIST 데이터셋을 사용하기 위해서는, 데이터셋의 이미지를 32x32로 크기를 변경해야 합니다.
실습.
# -*- coding: utf-8 -*-
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
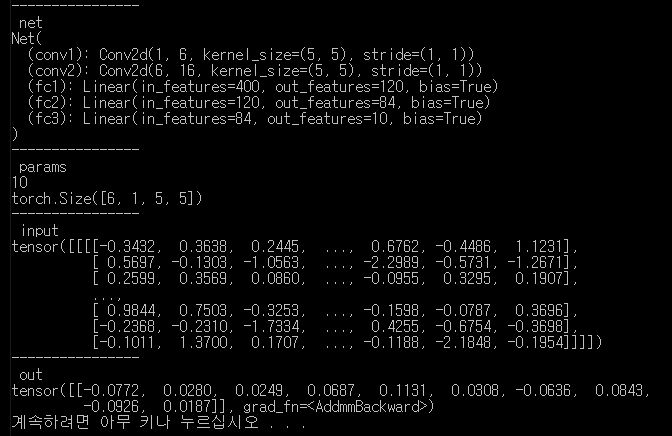
net = Net()
print("----------------\n net")
print(net)
params = list(net.parameters())
print("----------------\n params")
print(len(params))
print(params[0].size()) # conv1's .weight
input = Variable(torch.randn(1, 1, 32, 32))
print("----------------\n input")
print(input)
out = net(input)
print("----------------\n out")
print(out)
# 모든 매개변수의 변화도 버퍼(gradient buffer)를 0으로 설정하고, 무작위 값으로 역전파를 합니다
net.zero_grad()
out.backward(torch.randn(1, 10))
결과.
torch.nn 은 미니 배치(mini-batch)만 지원합니다.
torch.nn 패키지 전체는 하나의 샘플이 아닌, 샘플들의 미니배치만을 입력으로 받습니다.
예를 들어, nnConv2D 는 nSamples x nChannels x Height x Width 의 4차원 Tensor를 입력으로 합니다.
만약 하나의 샘플만 있다면, input.unsqueeze(0) 을 사용해서 가짜 차원을 추가합니다.
• torch.Tensor - 다차원 배열.
• autograd.Variable - Tensor를 감싸고 모든 연산을 기록 합니다. Tensor 와 동일한 API를 갖고 있으며, backward() 와 같이 추가된 것들도 있습니다. 또한, tensor에 대한 변화도를 갖고 있습니다.
• nn.Module - 신경망 모듈. 매개변수를 캡슐화(Encapsulation)하는 간편한 방법 으로, GPU로 이동, 내보내기(exporting), 불러오기(loading) 등의 작업을 위한 헬퍼(helper)를 제공합니다.
• nn.Parameter - 변수의 한 종류로, Module 에 속성으로 할당될 때 자동으로 매개변수로 등록 됩니다.
• autograd.Function - autograd 연산의 전방향과 역방향 정의 를 구현합니다. 모든 Variable 연산은 하나 이상의 Function 노드를 생성하며, 각 노드는 Variable 을 생성하고 이력(History)을 부호화 하는 함수들과 연결하고 있습니다.
손실 함수 (Loss Function)
손실 함수는 (output, target)을 한 쌍(pair)의 입력으로 받아, 출력(output)이 정답(target)으로부터 얼마나 떨어져있는지를 추정하는 값을 계산합니다.
nn 패키지에는 여러가지의 손실 함수들 이 존재합니다. 간단한 손실 함수로는 출력과 대상간의 평균자승오차(mean-squared error)를 계산하는 nn.MSEloss 가 있습니다.