10. SVM : BMI 데이터 분석
페이지 정보
작성자 관리자 댓글 0건 조회 3,599회 작성일 20-02-22 11:31본문
10. SVM : BMI 데이터 분석
SVM : (Support Vector Machine)
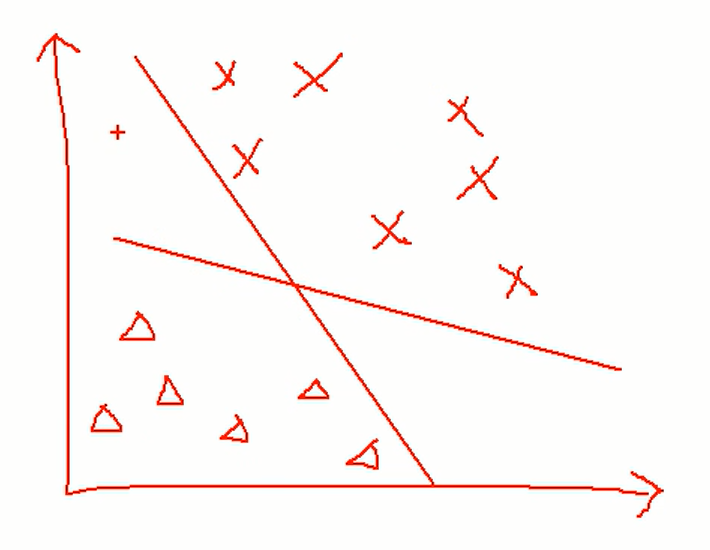
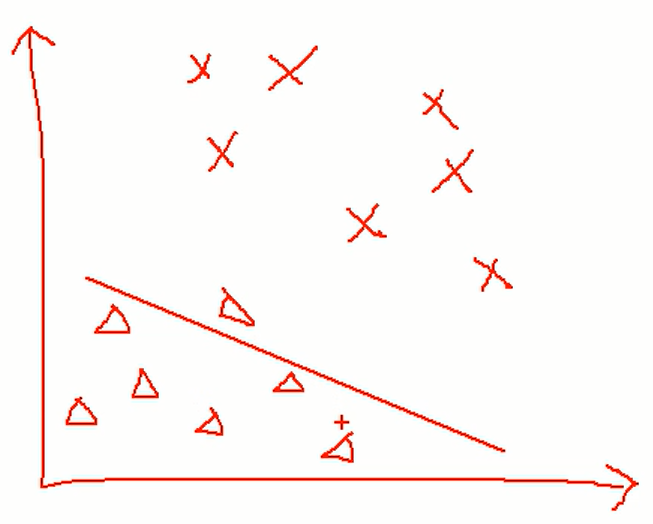
A패터과 B패턴이 있을 때 분류하는 알고리즘(분류기)
구분선을 이용하여 A패턴과 B패턴을 구분한다.
SVM은 구분선을 그리는 알고리즘이라 할 수 있다.
ㅍ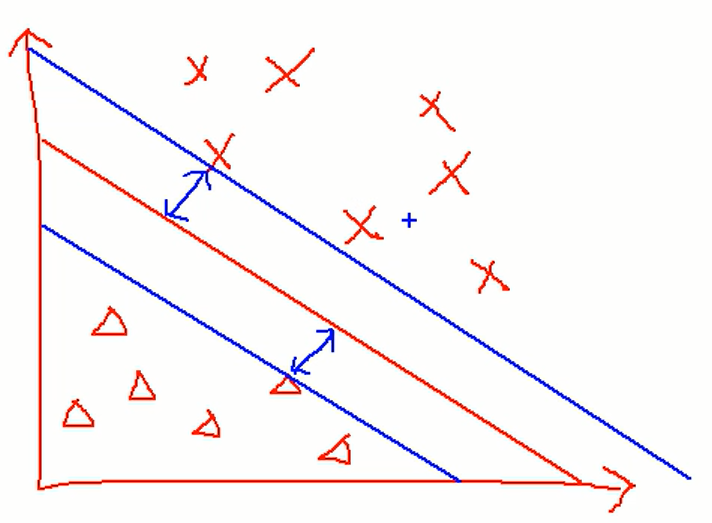
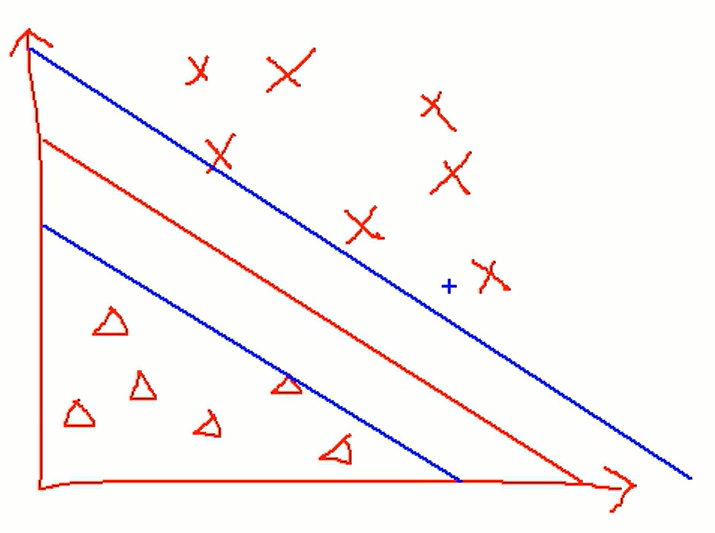
마진의 최대화 할 수 있는 구분선을 그려 각 패턴을 구분하게 된다.
# 1만명의 BMI데이터 만들기(CSV 파일)
# Body Mass Index(체질량 지수) 데이터 만들기
실습1.
# -*- coding: utf-8 -*-
import random
def bmi_func(height, weight):
bmi = weight/(height/100)**2
if bmi < 18.5: return "저체중"
if bmi < 25: return "정상"
return "비만"
fp = open("bmi.csv", "w", encoding="utf-8")
fp.write("height,weight,label\r\n")
# 데이터 생성하기
cnt = {"저체중":0, "정상":0, "비만":0}
for i in range(10000):
h = random.randint(120, 200)
w = random.randint(35, 90)
label = bmi_func(h, w)
cnt[label] +=1
fp.write("{0},{1},{2}\r\n".format(h, w, label))
fp.close()
print("ok, ", cnt)
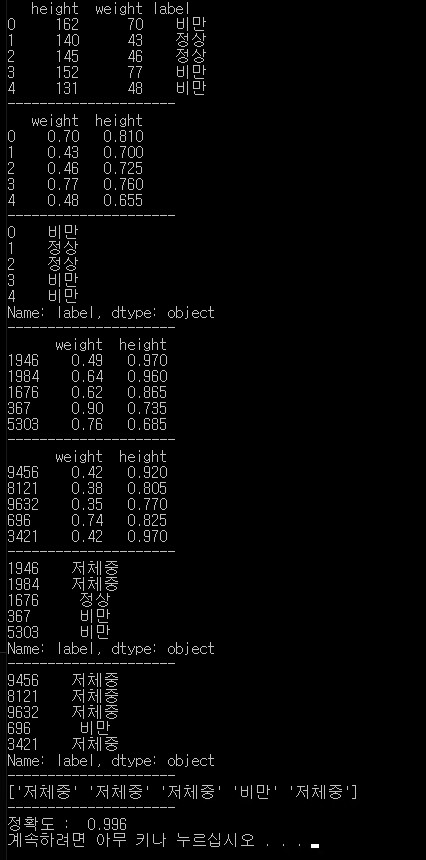
결과.

bmi.csv 파일이 생성된다.

실습2.
# -*- coding: utf-8 -*-
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
import pandas as pd
#키와 몸무게 데이터를 읽어 오기
data = pd.read_csv("bmi.csv")
print(data[:5])
print("---------------------")
# 컬럼(열) 분리
label = data["label"]
h = data["height"] / 200 # 정규화 과정 : 0 ~ 1 사이의 값으로 변환한다.
w = data["weight"] / 100
wh = pd.concat([w,h], axis=1)
print(wh[:5])
print("---------------------")
print(label[:5])
print("---------------------")
#학습 데이터와 테스트 데이터로 나누기
data_train, data_test, label_train, label_test =train_test_split(wh, label)
print(data_train[:5])
print("---------------------")
print(data_test[:5])
print("---------------------")
print(label_train[:5])
print("---------------------")
print(label_test[:5])
print("---------------------")
clf = svm.SVC()
clf.fit(data_train, label_train)
predict = clf.predict(data_test)
print(predict[:5])
print("---------------------")
ac_score = metrics.accuracy_score(label_test, predict)
print("정확도 : ", ac_score)
결과.