7. KNN
페이지 정보
작성자 관리자 댓글 1건 조회 5,063회 작성일 20-02-21 23:01본문
7. KNN
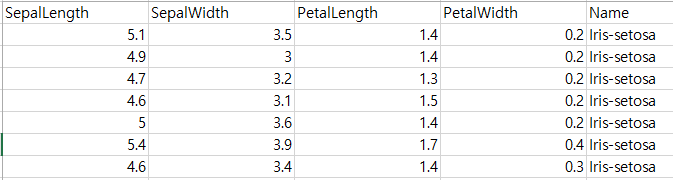
KNN(K Nearest Neighbors) : K-최근접 이웃 알고리즘
사용하기 쉬운 분류 알고리즘(분류기)중의 하나이다.
K의 의미는 가장 가까운 이웃 하나를 의미하는 것이 아니라,
훈련데이터에서 새로운 데이터에 가장 가까운 K개의 이웃을 찾는다는 의미이다.
세개 혹은 다섯개의 이웃을 찾는다.
# KNN을 사용하기 위해서는 neighbors모듈에 KNeighborsClassifier함수를 사용한다.
# KNeighborsClassifier()함수의 중요한 매개변수는 n_neighbors
# 이 매개변수는 이웃의 개수를 지정하는 매개변수이다.
실습1.
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
irisData = load_iris()
# scikit-learn 에서 데이터는 대문자 X로 표시하고 레이블은 소문자 y로 표시
X_train, X_test, y_train, y_test = train_test_split(
irisData['data'], irisData['target'], random_state=0)
#train_test_split()의 리턴 타입은 모듀 numpy 배열이다.
knn = KNeighborsClassifier(n_neighbors=1)
# 훈련 데이터셋을 가지고 모델을 만들려면 fit메서드를 사용한다.
# fit 메서드의 리턴값은 knn 객체를 리턴한다.
knn.fit(X_train, y_train)
# 채집한 붓꽃의 새로운 데이터(샘플)라고 가정하고 Numpy 배열로 특성값을 만든다.
# scikit-learn에서는 항상 데이터가 2차원 배열일 것으로 예측해야 한다.
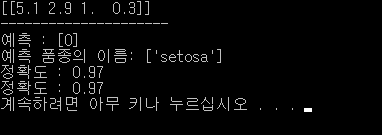
X_newData = np.array([[5.1, 2.9, 1, 0.3]])
print(X_newData)
print("---------------------")
# knn 객체의 predict() 메서드를 사용하여 예측할 수 있따.
prediction = knn.predict(X_newData)
print("예측 : {}".format(prediction))
print("예측 품종의 이름: {}".format(irisData['target_names'][prediction]))
y_predict = knn.predict(X_test)
# 정확도를 계산하기 위해서 numpy의 mean()메서드를 이용
# knn객체의 score()메서드를 사용해도 된다.
print("정확도 : {:.2f}".format(np.mean(y_predict == y_test)))
print("정확도 : {:.2f}".format(np.mean(y_predict == y_test)))
결과.
정확도를 계산하기 위해서 numpy의 mean()메서드를 이용
실습2.
# -*- coding: utf-8 -*-
import numpy as np
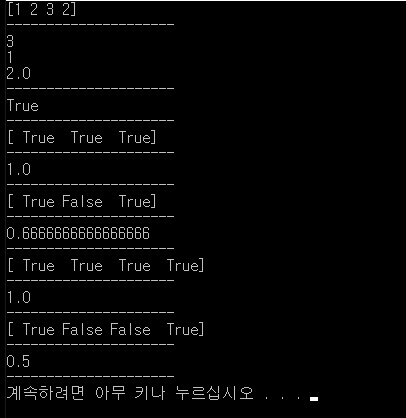
x = np.array([1,2,3,2])
print(x)
print("---------------------")
print(x.max())
print(x.min())
print(x.mean())
print("---------------------")
a = 1;
b = 1
print(a == b)
print("---------------------")
a = np.array([1,2,3])
b = np.array([1,2,3])
print(a == b)
print("---------------------")
print(np.mean(a == b))
print("---------------------")
b = np.array([1,1,3])
print(a == b)
print("---------------------")
print(np.mean(a == b))
print("---------------------")
a = np.array([1,2,3,4])
b = np.array([1,2,3,4])
print(a == b)
print("---------------------")
print(np.mean(a == b))
print("---------------------")
b = np.array([1,1,1,4])
print(a == b)
print("---------------------")
print(np.mean(a == b))
print("---------------------")
결과.
# iris분류 문제에 있어서 각품종을 클래스라고 한다.
# 개별 붓꽃의 품종은 레이블 이라고 한다.
# 붓꽃의 데이터 셋은 두개의 Numpy 배열로 이루어져 있다.
# 하나는 데이터, 다른 하나는 출력을 가지고 있다.
# scikit-learn에서는 데이터는 X로 표기하고, 출력은 y로 표기한다.
# 이때 배열X는 2차원 배열이고 각행은 데이터포인트(샘플)에 해당한다.
# 각 컬럼(열)은 특성이라고 한다.
# 배열 y는 1차원 배열이고, 각 샘플의 클래스 레이블에 해당한다.
iris 각 품종의 특성의 4가지로 꽃잎2가지와 꽃밭침 2가지로 나누어 있다.