9. 다중 색인
페이지 정보
작성자 관리자 댓글 0건 조회 3,565회 작성일 20-02-18 22:12본문
9. 다중 색인
# 다중 색인(multi index)
# 색인의 계층 : pandas의 중요 기능 중의 하나로 다중 색인 단계를 지정할 수 있다.
실습1.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
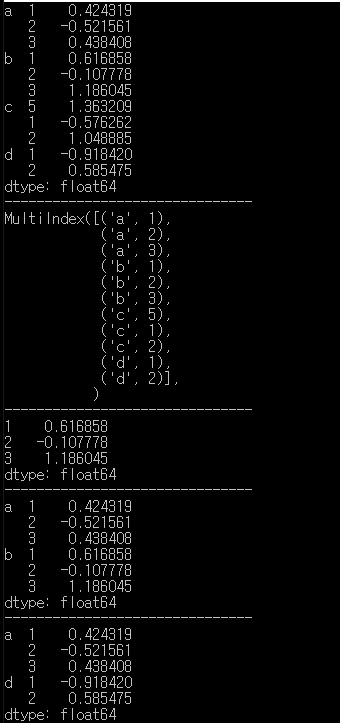
data = Series(np.random.randn(11),
index = [['a','a','a','b','b','b','c','c','c','d','d'],
[1,2,3,1,2,3,5,1,2,1,2]])
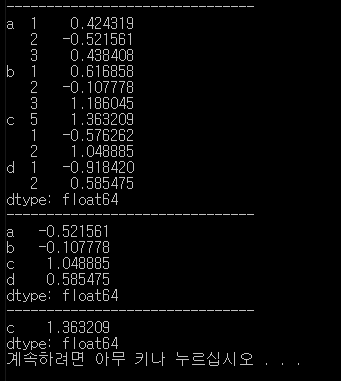
print(data)
print("-------------------------------")
print(data.index)
print("-------------------------------")
print(data['b'])
print("-------------------------------")
print(data['a':'b'])
print("-------------------------------")
print(data.loc[['a', 'd']])
print("-------------------------------")
print(data)
print("-------------------------------")
print(data[:, 2])
print("-------------------------------")
print(data[:, 5])
결과.
실습2.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
df = DataFrame(np.arange(12).reshape(4,3),
index=[['a','a', 'b', 'b'],[1,2,1,2]],
columns=[['seoul', 'busan', 'kwangju'], ['red', 'green', 'red']])
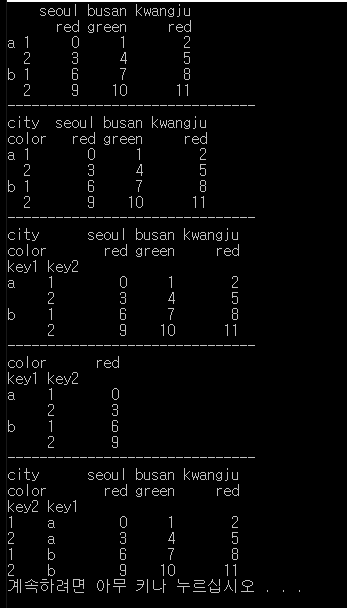
print(df)
print("-------------------------------")
#컬럼 색인의 이름 정하기
df.columns.names=['city', 'color']
print(df)
print("-------------------------------")
df.index.names=['key1', 'key2']
print(df)
print("-------------------------------")
print(df['seoul'])
print("-------------------------------")
# 색인계층의 순서를 바꾸기
# swaplevel() 메소드를 이용해서 바꾼다
print(df.swaplevel('key1', 'key2')) # key1과 key2를 바꾸겠다
결과.
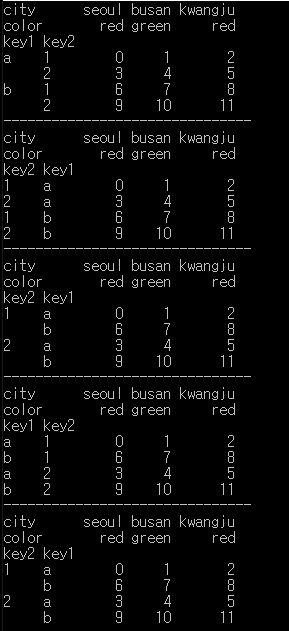
실습3.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
df = DataFrame(np.arange(12).reshape(4,3),
index=[['a','a', 'b', 'b'],[1,2,1,2]],
columns=[['seoul', 'busan', 'kwangju'], ['red', 'green', 'red']])
#컬럼 색인의 이름 정하기
df.columns.names=['city', 'color']
df.index.names=['key1', 'key2']
print(df)
print("-------------------------------")
# 사전식으로 계층을 바꾸어서 정렬하기
# sort_values()메소드를 이용해서 정렬한다.
df2 = df.swaplevel('key1','key2')
print(df2)
print("-------------------------------")
print(df2.sort_values(by='key2'))
print("-------------------------------")
df3=df.sort_values(by='key2')
print(df3)
print("-------------------------------")
print(df3.swaplevel(0,1))
print("-------------------------------")
print(df.swaplevel(0,1))
print("-------------------------------")
print(df.swaplevel(0,1).sort_values(by='key2'))
print("-------------------------------")
print(df.sort_values(by='key2').swaplevel(0,1))
print("-------------------------------")
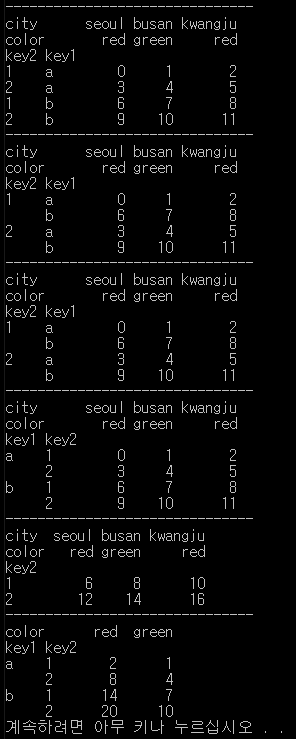
print(df)
print("-------------------------------")
print(df.sum(level='key2'))
print("-------------------------------")
print(df.sum(level='color', axis=1))
결과.
실습4.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
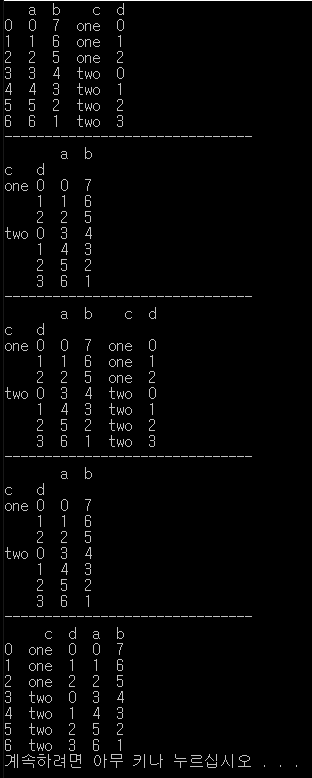
df = DataFrame({'a':range(7), 'b':range(7,0,-1),
'c':['one', 'one', 'one', 'two', 'two', 'two', 'two'],
'd':[0,1,2,0,1,2,3]})
print(df)
print("-------------------------------")
#set_index 메서드 : 하나 이상의 칼럼을 색인으로 하는 새로운 DataFrame을 생성
print(df.set_index(['c', 'd']))
print("-------------------------------")
print(df.set_index(['c','d'], drop=False))
print("-------------------------------")
#set_index와 반대되는 개념의 메서드 : reset_index() -> 색인을 컬럼으로
df2 = df.set_index(['c', 'd'])
print(df2)
print("-------------------------------")
print(df2.reset_index())
결과.