8. 기술통계 메소드
페이지 정보
작성자 관리자 댓글 1건 조회 4,171회 작성일 20-02-18 20:03본문
8. 기술통계 메소드
# 기술 통계 계산
# pandas 는 일반적인 수학/통계 메서드를 가지고 있다.
# pandas의 메서드는 처음부터 누락된 데이터를 제외하도록 설계되어 있다.
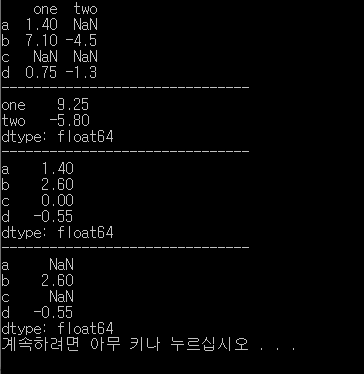
실습1.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
df = DataFrame([[1.4, np.nan], [7.1, -4.5],[np.nan, np.nan],[0.75, -1.3]],
index=['a', 'b', 'c', 'd'],
columns=['one', 'two'])
print(df)
print("-------------------------------")
#sum()메서드는 각 컬럼의 합을 더해서 Series 객체를 반환한다.
print(df.sum())
print("-------------------------------")
print(df.sum(axis=1)) #각행의 합을 반환한다.
print("-------------------------------")
# 전체 행이나 칼럼의 값이 NA가 아니라면 NA 값은 제외시키고 계산을 하는데
# skipna옵션은 전체 행이나 칼럼의 값이 NA가 아니라도 제외시키지 않을 수 있다.
# skipna의 기본값은 True
print(df.sum(axis=1, skipna=False))
결과.
실습2.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
df = DataFrame([[1.4, np.nan], [7.1, -4.5],[np.nan, np.nan],[0.75, -1.3]],
index=['a', 'b', 'c', 'd'],
columns=['one', 'two'])
print(df)
print("-------------------------------")
# idxmin, idxmax와 같은 메서드는 최소, 최대값을 가지고 있는 색인 값 같은
# 간접 통계를 반환한다.
print(df.idxmax())
print("-------------------------------")
# 누산 메서드 : cumsum()
print(df.cumsum())
결과.
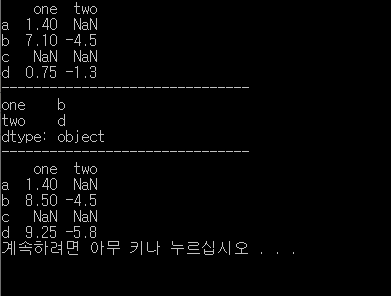
실습3.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
# 유일한 값, 도수 메서드
s1 = Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
unique = s1.unique() # 중복값을 없애는 메서드
print(unique) #unique()에 의한 결과값은 정렬되지 않은 상태로 반환된다.
print("-------------------------------")
cnt = s1.value_counts() # 값의 수를 계산(도수), 반환값은 Series 객체
print(cnt) # 내림차순으로 정렬된다.
print("-------------------------------")
# isin 메서드는 어떤 값이 Series에 있는지 나타내는 메소드
# 불리언 값(True, False)을 반환한다.
# DataFrame, Series에서 원하는 값을 골라내고 싶을 때 유용하게 사용하는 메소드
print(s1)
print("-------------------------------")
mask = s1.isin(['b', 'c'])
print(mask)
print("-------------------------------")
print(s1[mask])
결과.
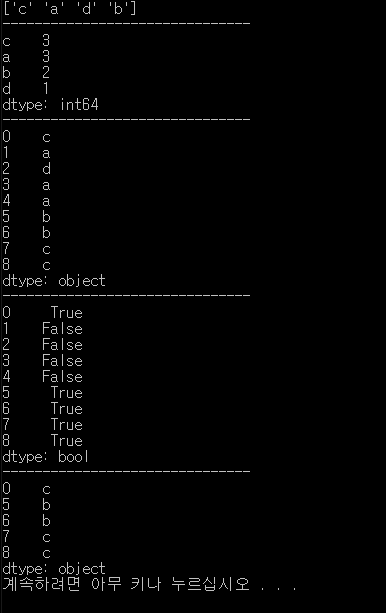
실습4.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
data = DataFrame({'Q1' : [1,3,4,3,4],
'Q2':[2,3,1,2,3],
'Q3':[1,5,2,4,4]})
print(data)
print("-------------------------------")
res = data.apply(pd.value_counts)
print(res)
print("-------------------------------")
res = data.apply(pd.value_counts).fillna(0)
print(res)
결과.
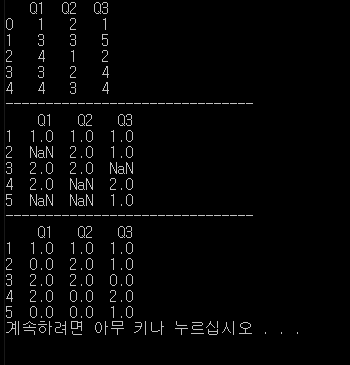
실습5.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
# 누락된 데이터 처리(pandas 의 설계 목표 중 하나는 누락된 데이터를 쉽게 처리하는 것)
#pandas 에서는 누락된 데이터를 실수든 아니든 모두 NaN(Not a Number)으로 취급한다.
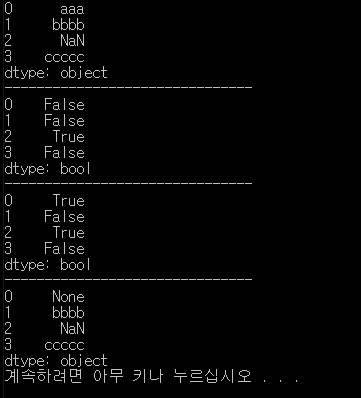
stringData = Series(['aaa', 'bbbb', np.nan, 'ccccc'])
print(stringData)
print("-------------------------------")
# 이러한 NaN의 값은 파이썬의 None값 NA와 같은 값으로 취급된다.
print(stringData.isnull())
print("-------------------------------")
stringData[0] = None
print(stringData.isnull())
print("-------------------------------")
print(stringData)
결과.
# 누락된 데이터 골라내기
# dropna함수를 이용하는 방법 등 여러 방법이 있을 수 있다.
# dropna를 사용하는 것이 유용한 방법이며, 사용 결과값으로 Series객체를 반환
실습6.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
from numpy import nan as NA
import pandas as pd
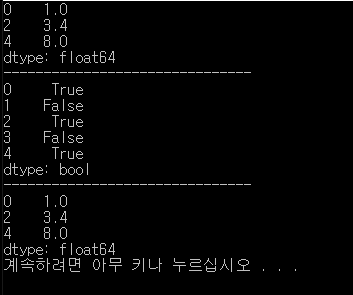
data = Series([1,NA, 3.4, NA, 8])
print(data.dropna())
print("-------------------------------")
# 불리언 색인을 이용해서 직접 계산한 후에 가져오기
print(data.notnull())
print("-------------------------------")
print(data[data.notnull()])
결과.
# DataFrame에서 누락된 데이터를 골라 내기
# dropna는 기본적으로 NA값이 하나라도 있는 로우는 제외시킨다.
실습7.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
from numpy import nan as NA
import pandas as pd
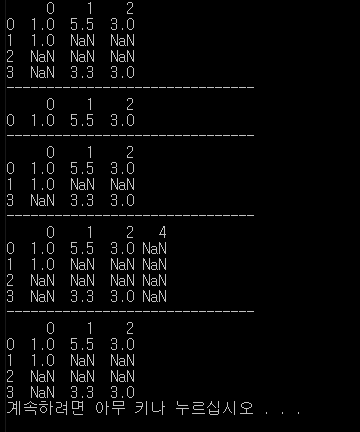
data = DataFrame([[1,5.5,3], [1,NA,NA], [NA, NA, NA], [NA, 3.3, 3]])
print(data)
print("-------------------------------")
print(data.dropna())
print("-------------------------------")
#how='all' 옵션을 주면 모든 값이 NA인 행만 제외된다.
print(data.dropna(how='all'))
print("-------------------------------")
data[4] = NA
print(data)
print("-------------------------------")
print(data.dropna(how='all', axis=1))
결과.
# 누락된 값을 채우기
# 데이터 프레임에서는 누락된 데이터를 완벽하게 골라낼 수 가 없으므로
# 다른 데이터도 함께 버려지게 된다. 이런 경우에는 fillna메서드를 활용해서
# 비어있는 값(구멍)을 채워주면 데이터의 손실을 막을 수 있다.
실습8.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
from numpy import nan as NA
import pandas as pd
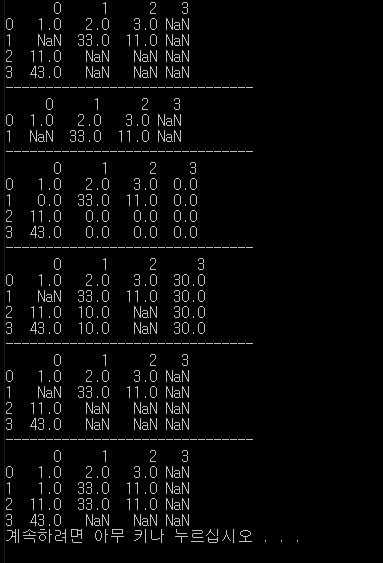
data2 = DataFrame([[1,2,3,NA],[NA, 33, 11,NA],[11,NA,NA,NA],[43, NA, NA, NA]])
print(data2)
print("-------------------------------")
# 몇개의 value가 들어 있는 행을 가져오고 싶을 경우 사용되는 인자는 thresh
print(data2.dropna(thresh=2))
print("-------------------------------")
print(data2.fillna(0))
print("-------------------------------")
#fillna의 활용에 따라 각 칼럼마다 다른 값을 채워넣을 수 있다.
print(data2.fillna({1:10, 3:30}))
print("-------------------------------")
print(data2)
print("-------------------------------")
print(data2.fillna(method='ffill', limit = 1))
결과.
실습9.
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
from numpy import nan as NA
import pandas as pd
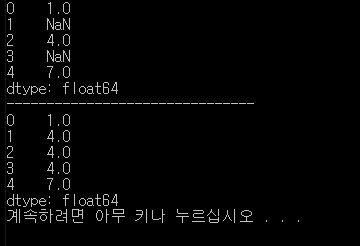
data3 = Series([1, NA, 4, NA, 7])
print(data3)
print("-------------------------------")
print(data3.fillna(data3.mean()))
결과.
댓글목록
관리자님의 댓글
관리자 작성일NA : Not Available