7. 와인 분류하기
페이지 정보
작성자 관리자 댓글 0건 조회 4,028회 작성일 20-02-25 21:09본문
7. 와인 분류하기
실제 데이터를 사용해서 분류 문제를 해결해 보겠다.
진행 순서는 다음과 같다.
- 학습데이터 준비
- 텐서 생성
- 신경망 구성
- 모형학습
1. 학습데이터 준비
실습1. 와인 데이터 읽어 들이기
# -*- coding: utf-8 -*-
# PyTorch 라이브러리 임포트
import torch
# scikit-learn 라이브러리 임포트
from sklearn.datasets import load_wine
# 와인 데이터 읽어 들이기
wine = load_wine()
print(wine)
결과.
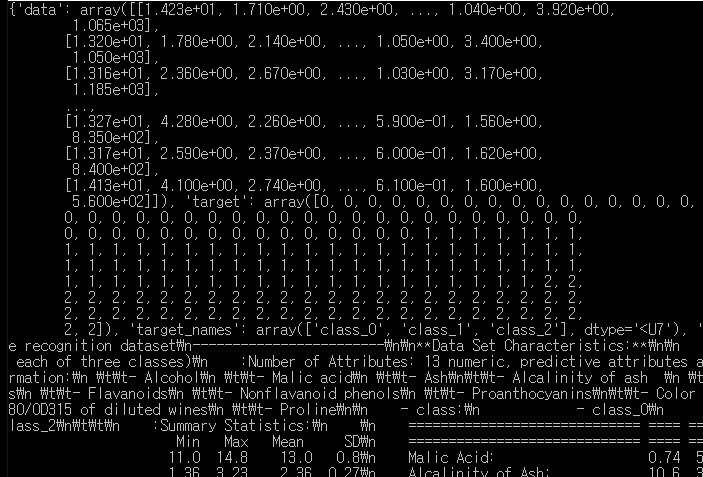
사이킷런에 포함된 데이터 집합을 학습 데이터로 사용할 것이다.
와인데이터 집합을 읽어들여 wine 변수에 저장한다.
wine 변수에는 다음과 같은 필드가 담겨 있다.
- DESCR : 데이터 집합의 상세 정보
- data : 와인 성분 데이터(설명변수)
- feature_names : 와인의 성분명
- target : 와인의 품종(목적변수)
- target_names : 와인의 품종이름
실습2. 와인 정보 조회하기
# -*- coding: utf-8 -*-
# PyTorch 라이브러리 임포트
import torch
# scikit-learn 라이브러리 임포트
from sklearn.datasets import load_wine
# 와인 데이터 읽어 들이기
wine = load_wine()
# 목적변수 데이터 출력
print(wine.target)
print("--------------------")
print(wine.target_names)
print("--------------------")
# 설명변수와 목적변수를 변수에 대입
wine_data = wine.data[0:130]
wine_target = wine.target[0:130]
print(wine_data)
print("--------------------")
print(wine_target)
print("--------------------")
결과.
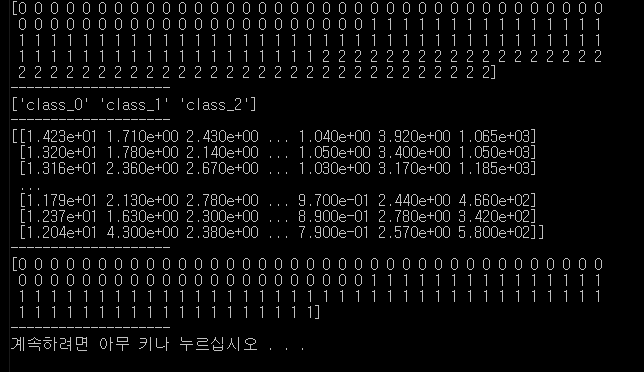
실습3. 훈련데이터와 테스트 데이터 분할
# -*- coding: utf-8 -*-
# PyTorch 라이브러리 임포트
import torch
# scikit-learn 라이브러리 임포트
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 와인 데이터 읽어 들이기
wine = load_wine()
# 설명변수와 목적변수를 변수에 대입
wine_data = wine.data[0:130]
wine_target = wine.target[0:130]
# 데이터 집합을 훈련 데이터와 테스트 데이터로 분할
train_X, test_X, train_Y, test_Y = train_test_split(wine_data, wine_target, test_size=0.2)
# 데이터 건수 확인
print(len(train_X))
print(len(test_X))
결과.

훈련데이터 설명변수의 변수명은 train_X, 목적변수의 변수명은 train_Y, 테스트 데이터 설명변수의 변수명은 text_X, 목젹변수의 변숨수명은 test_Y로 한다.
2. 텐서 생성
준비가 끝난 데이터를 파이토치가 다룰 수 있는 형태로 정리한다.
실습4.
# -*- coding: utf-8 -*-
# PyTorch 라이브러리 임포트
import torch
# scikit-learn 라이브러리 임포트
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 와인 데이터 읽어 들이기
wine = load_wine()
# 설명변수와 목적변수를 변수에 대입
wine_data = wine.data[0:130]
wine_target = wine.target[0:130]
# 데이터 집합을 훈련 데이터와 테스트 데이터로 분할
train_X, test_X, train_Y, test_Y = train_test_split(wine_data, wine_target, test_size=0.2)
# 데이터 건수 확인
print(len(train_X))
print(len(test_X))
# 훈련 데이터 텐서 변환
train_X = torch.from_numpy(train_X).float()
train_Y = torch.from_numpy(train_Y).long()
# 테스트 데이터 텐서 변환
test_X = torch.from_numpy(test_X).float()
test_Y = torch.from_numpy(test_Y).long()
# 텐서로 변환한 데이터 건수 확인
print(train_X.shape)
print(train_Y.shape)
결과.

orch.from_numpy(test_X)는 Numpy 배열을 텐서(Tensor)로 변한한다.
실습5.
# -*- coding: utf-8 -*-
# PyTorch 라이브러리 임포트
import torch
from torch.utils.data import DataLoader, TensorDataset
# scikit-learn 라이브러리 임포트
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 와인 데이터 읽어 들이기
wine = load_wine()
# 설명변수와 목적변수를 변수에 대입
wine_data = wine.data[0:130]
wine_target = wine.target[0:130]
# 데이터 집합을 훈련 데이터와 테스트 데이터로 분할
train_X, test_X, train_Y, test_Y = train_test_split(wine_data, wine_target, test_size=0.2)
# 데이터 건수 확인
print(len(train_X))
print(len(test_X))
# 훈련 데이터 텐서 변환
train_X = torch.from_numpy(train_X).float()
train_Y = torch.from_numpy(train_Y).long()
# 테스트 데이터 텐서 변환
test_X = torch.from_numpy(test_X).float()
test_Y = torch.from_numpy(test_Y).long()
# 텐서로 변환한 데이터 건수 확인
print(train_X.shape)
print(train_Y.shape)
# 설명변수와 목적변수의 텐서를 합침
train = TensorDataset(train_X, train_Y)
# 텐서의 첫 번째 데이터 내용 확인
print(train[0])
# 미니배치로 분할
train_loader = DataLoader(train, batch_size=16, shuffle=True)
결과.
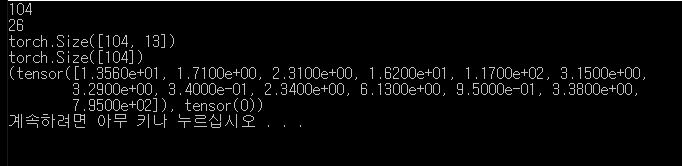
설명변수와 목적변수의 텐서를 합쳐서 train이라는 이름으로 훈련데이터 집합을 만든다.
미니배치 학습을 수행하기 위해 데이터 집합을 셔플링해서 16개 단위로 분할 한다.
분할한 데이터를 train_loader라는 이름으로 저장한다.
3. 신경망 구성
이제 학습에 사용할 신경망을 구성할 차례이다.
입력층, 중간층, 출력층이 하나씩 있는 신경망을 구성한다.
입력층의 노드 수는 13개(설명변수의 개수)이고, 중간층 노드의 수는 96개, 출력층 노드의 수는 2개(목적변수의 개수)다.
실습6.
import torch
import torch.nn as nn
import torch.nn.functional as F
# 신경망 구성
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 96)
self.fc2 = nn.Linear(96, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x)
# 인스턴스 생성
model = Net()
Net 클래스 안에 신경망을 구성한다. 생성자 메소드에서 입력층과 중간층 사이의 결합, 중간층과 출력층 사이의 집합, 그리고 각층의 노드 수를 정의한다.
forward 메서드에서는 활성화 함수를 정의하는데, 중간층에는 ReLU함수를 사용하고 출력층은 소프트맥스 함수를 사용한다.
model이라는 이름으로 이 클래스의 인스턴스를 생성한다.
모든 신경망 모듈의 기본이 되는 클래스다. 이 클래스 안에 각 층과 함수, 신경망의 구조를 정의한다.
nn.Linear(13, 96)
입력데이터에 대한 선형 변환(y = Ax+b)을 계산한다.
in_features : 입력데이터의 차원수
out_features: 출력데잍이터의 차원수
bias : 바이엇 학습 여부 기본값은 True이다.
F.relu(self.fc1(x))
ReLU 함수를 구현한 함수다.
F.log_softmax(x)
로그 소프트맥스 함수를 구현한 함수다.
4. 모형 학습
전 단계에서 만든 텐서를 신경망에 입력해 모형을 학습해 본다.
그 다음 학습된 모형의 정확도를 측정해 볼 것이다.
실습7.
# -*- coding: utf-8 -*-
# PyTorch 라이브러리 임포트
import torch
from torch.utils.data import DataLoader, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
# scikit-learn 라이브러리 임포트
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 와인 데이터 읽어 들이기
wine = load_wine()
# 설명변수와 목적변수를 변수에 대입
wine_data = wine.data[0:130]
wine_target = wine.target[0:130]
# 데이터 집합을 훈련 데이터와 테스트 데이터로 분할
train_X, test_X, train_Y, test_Y = train_test_split(wine_data, wine_target, test_size=0.2)
# 데이터 건수 확인
print(len(train_X))
print(len(test_X))
# 훈련 데이터 텐서 변환
train_X = torch.from_numpy(train_X).float()
train_Y = torch.from_numpy(train_Y).long()
# 테스트 데이터 텐서 변환
test_X = torch.from_numpy(test_X).float()
test_Y = torch.from_numpy(test_Y).long()
# 텐서로 변환한 데이터 건수 확인
print(train_X.shape)
print(train_Y.shape)
# 설명변수와 목적변수의 텐서를 합침
train = TensorDataset(train_X, train_Y)
# 텐서의 첫 번째 데이터 내용 확인
print(train[0])
# 미니배치로 분할
train_loader = DataLoader(train, batch_size=16, shuffle=True)
# 신경망 구성
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 96)
self.fc2 = nn.Linear(96, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim = -1)
# 인스턴스 생성
model = Net()
# 오차함수 객체
criterion = nn.CrossEntropyLoss()
# 최적화를 담당할 객체
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 학습 시작
for epoch in range(300):
total_loss = 0
# 분할해 둔 데이터를 꺼내옴
for train_x, train_y in train_loader:
# 계산 그래프 구성
train_x, train_y = Variable(train_x), Variable(train_y)
# 경사 초기화
optimizer.zero_grad()
# 순전파 계산
output = model(train_x)
# 오차계산
loss = criterion(output, train_y)
# 역전파 계산
loss.backward()
# 가중치 업데이트
optimizer.step()
# 누적 오차 계산
total_loss += loss.data[0]
# 50회 반복마다 누적오차 출력
if (epoch+1) % 50 == 0:
print(epoch+1, total_loss)
# 계산 그래프 구성
test_x, test_y = Variable(test_X), Variable(test_Y)
# 출력이 0 혹은 1이 되게 함
result = torch.max(model(test_x).data, 1)[1]
# 모형의 정확도 측정
accuracy = sum(test_y.data.numpy() == result.numpy()) / len(test_y.data.numpy())
# 모형의 정확도 출력
print(accuracy)
결과.