9. SVM : 붓꽃데이터 분석 (Pandas 이용)
페이지 정보
작성자 관리자 댓글 0건 조회 3,644회 작성일 20-02-22 10:57본문
9. SVM : 붓꽃데이터 분석 (Pandas 이용)
실습.
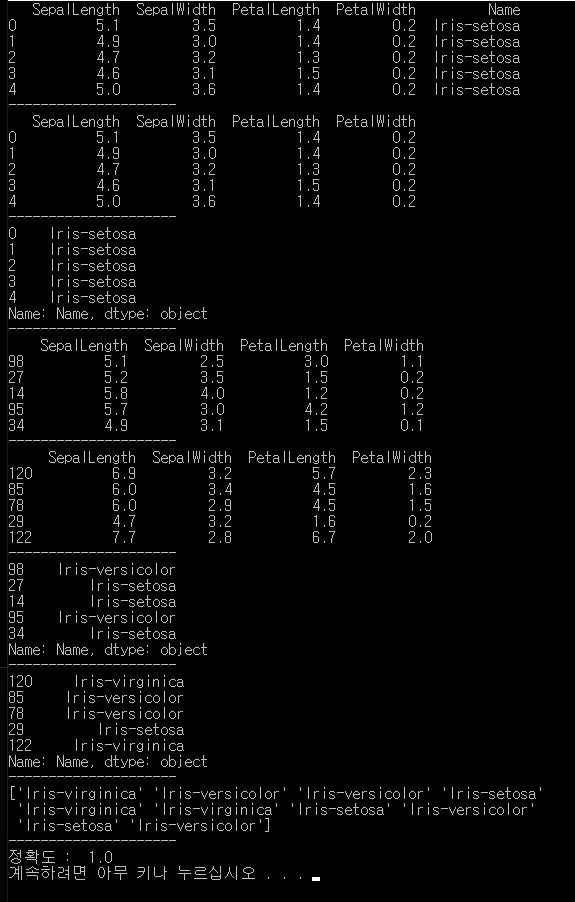
# -*- coding: utf-8 -*-
import pandas as pd
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
#데이터 읽어오기(pandas 이용하기)
csv = pd.read_csv('iris.csv')
print(csv[:5])
print("---------------------")
# 데이터와 레이블 분리하기
csv_data = csv[["SepalLength", "SepalWidth", "PetalLength", "PetalWidth"]]
csv_label = csv["Name"]
print(csv_data[:5])
print("---------------------")
print(csv_label[:5])
print("---------------------")
# 훈련 데이터와 테스트 데이터로 분리하기
X_train, X_test, y_train, y_test = train_test_split(csv_data, csv_label)
print(X_train[:5])
print("---------------------")
print(X_test[:5])
print("---------------------")
print(y_train[:5])
print("---------------------")
print(y_test[:5])
print("---------------------")
clf = svm.SVC()
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
print(y_predict[:10])
print("---------------------")
ac_score = metrics.accuracy_score(y_test, y_predict)
print("정확도 : " , ac_score)
결과.