| Web Programming >> PHP Programming
|
| [목차] |
|
제17장 데이터베이스 기초 및 설계
2. 데이터의 저장
이 장에서는 데이타베이스의 데이타가 실제로 어떤 형식으로 저장매체에 저장되는지 를 살펴보겠습니다. 데이타베이스는 대부분의 경우 많은 양의
데이타를 가지고 있기 때문에 이들을 저장하기 위해서는 비교적 값싸면서도 많은 데이타를 저장할 수 있는 하드 디스크와 같은 매체에 저장됩니다.
이러한 디스크에 자료를 쓰거나 읽는 작업의 경우, 내부 메모리에서의 작업에 비해 훨씬 많은 시간이 걸리므로 디스크에서의 읽기및 쓰기 작업을
최소화하는 것이 데이타베이스에서 매우 중요한 관건이 됩니다. 디스크에 데이타가 저장될 때 데이타들은 관련된 것들 끼리 묶여서 저장된는 데 이러한 데이타의 묶음을 레코드라고 합니다. 즉 학사관리
시스템의 예를 든다면 한 학생에 대한 데이타를 학번, 이름, 학과, 출생년도의 세개의 부분으로 구성된 레코드로 저장할 수 있을 것입니다. 이러한
레코드는 데이타가 저장되는 기본단위로써 하나의 화일을 구성합니다. 레코드들의 집합으로써의 화일은 그 내부에서 레코드들이 배열된 형태에 따라 여러가지 종류가 있습니다. 아무런 순서없이 배열되어 있거나, 또는
레코드의 특정한 값에 따라 순서대로 정렬되어있거나, 또는 해쉬와 같은 방법으로 배열할 수도 있습니다. 이러한 화일에 대해서는 필요한 레코드를 찾기, 새로운 레코드를 추가, 레코드의 삭제등의 작업을 수행할 수 있습니다. 책에서 자료를 찾을 때 흔히 맨 뒤에 있는 인덱스를 이용하는 것처럼 화일내에서 필요한 레코드를 찾을 때 인덱스를 찾아 봄으로써 전체 화일을
찾을 때보다 훨씬 효율적으로 작업할 수 있습니다.. 이러한 인덱스를 어떻게 구현함으로써 데이타에 대한 접근을 빨리 할 수 있을 지를 알아보도록
하겠습니다. 4.2.1. 레코드 : 데이타 저장의 기본 단위 4.2.1.1. 레코드의 정의 레코드는 데이타저장의 기본단위 입니다. 학생의 데이타를 나타내고자 할 때, 한 학생의 대한 학번, 이름, 학과, 출생년도는 하나의 단위로
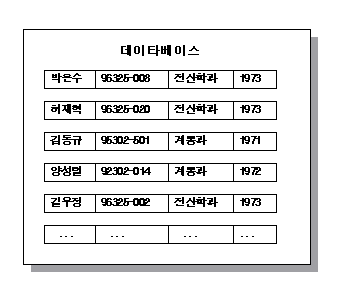
저장됩니다. 만약 학번들을 따로 모으고 이름을 따로 모으는 식이라면 아무런 정보도 나타낼 수 없을 것입니다. 이와 같이 나타내고자 하는 대상에 관련된 값들을 모아서 하나의 단위를 만든 것이 레코드이며 데이타베이스의 저장된 모든 데이타는 이 레코드의 단위로 저장됩니다. 이처럼 관련된 데이타를 레코드 단위로 묶음으로써 한 학생의 데이타라고 하면 그 학생의 학번, 이름, 학과, 출생년도등을 말한다는 것을 알 수있습니다. 학생데이타를 레코드로 나타냈을 때는 다음과 같이 표현할 수 있습니다.
레코드의 각부분은 출생년도와 같이 숫자로 될 수도 있을 것이고, 이름과 같이 문자열 로 이루어져 있을 수도 있을 것입니다. 이처럼 하나의
레코드는 서로 다른 형태의 값을 가질 수 있는 부분들로 나누져있으며 레코드를 정의할 때는 프로그래밍 언어에서 사용하는 방법을 써 나타낼 수
있습니다. type 학생레코드 = {
4.2.1.2. 레코드의 길이 레코드를 실제로 디스크에 저장한다고 할 때 어떻게 각 부분들을 구별할 수 있을까요? 이런 경우 두가지 경우로 나누어 생각해 볼 수 있습니다. 첫번째로 레코드의 각 부분의 크기가 고정된 경우일 때는 각 부분의 크기를 알고 있으므로 별다른 표시없이 데이타의 각 부분을 구별할 수 있읍니다. 예를 들어 학생의 이름은 20바이트, 학과는 20바이트 학번을 10바이트 식으로 고정되어 있다면 그 크기만큼씩만 읽어서 각 부분을 구별할 수 있습니다.
두번째 경우 만약 레코드를 이루는 부분중 한두개 또는 모든 부분의 크기가 고정되어 있지 않다면 각 부분마다 끝을 표시하기위한 필요하게 됩니다. 즉 아래의 예와 같이 특별한 문자를 써서 그부분의 끝을 나타낼 수 있습니다.
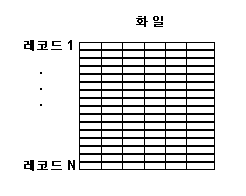
4.2.2. 레코드들의 집합 : 화일 4.2.2.1. 화일의 정의 화일은 레코드들의 집합입니다. 학생 데이타들을 저장할 때, 학생에 관한 모든 레코드들 모으면 이것이 학생 화일을 이루게 됩니다. 이러한
레코드들이 화일 내에서 배열된 형태에 따라 여러가자 화일의 구조를 만들 수 있습니다. 우선 첫번째로 화일안에서 레코드들은 아무런 순서없이 새로운 레코드가 추가될 때마다 화일의 끝에 추가시킬 수 있습니다. 두번째로 레코드의
특정한 한 부분의 값. 예를 들어 학생의 학번등의 값에 따라 순서대로 화일내에 배열시킬 수도 있습니다. 하지만 순서대로 레코드를 배열하는 경우에는 레코드를 찾을 때 잇점이 있을 수 있지만, 새로운 레코드를 추가하거나 기존 레코드를 삭제하는 경우 순서를 유지하기위해 복잡한 작업을 해야만 합니다. 위의 두가지 배열이외에도 해쉬구조를 이용하여 화일을 구성할 수도 있습니다.
4.2.2.2. 화일에 대한 작업들 1. 찾기 (FIND) 예를 들어 학번이 92302-024인 학생의 레코드를 찾는다거나 출생년도가 1974년 이후인 학생의 레코드를 찾는 것과 같이 조건이
주어졌을 때, 그 조건을 만족하는 레코드를 골라내는 작업입니다. 2. 레코드의 읽기 (READ) 조건에 의해서 레코드를 찾았을 때 실제로 이 레코드를 디스크로 부터 읽어오는 작업입니다. 3. 레코드의 추가 (INSERT) 새로운 레코드를 화일에 추가시키는 작업입니다. 4. 레코드의 삭제 (DELETE) 찾은 레코드를 화일에서 없애는 작업입니다. 5. 레코드의 변경 (MODIFY) 레코드의 내용을 바꾸는 작업입니다. 6. 레코드를 처음부터 읽기 화일내에 있는 레코드를 처음부터 하나씩 읽는 작업입니다.
4.2.3. 레코드로의 지름길 : 인덱스 4.2.3.1. 인덱스의 정의 데이타베이스의 화일에서 우리가 원하는 특정한 레코드를 찾는 경우를 생각해봅시다. 가장 쉽게 생각할 수 있는 방법은 처음부터 찾아가서 끝가지
모두를 검사해보는 방법이 있을 것입니다. 이러한 방법은 얼핏 보기에도 매우 비효율적으로 보입니다. 실제로 데이타베이스에서 원하는 자료를 찾을 때 디스크에서 읽어오는 시간이 전체 걸리는 시간에서 많은 부분을 차지하고 있기 때문에 되도록
디스크를 직접 쓰거나 읽는 것을 줄이는 것이 매우 중요한 문제가 됩니다. 그런데 위와 같이 처음부터 화일을 찾아간다면 하나의 레코드를 찾기
위해서도 전체 화일을 읽어야 할 것입니다. 위의 방법과 달리 백과사전에서 단어에 대한 설명을 찾을 때를 생각해봅시다. 보통의 백과사전은 대부분 색인사전을 가지고 여기서 단어를 찾으면
필요한 내용이 있는 사전의 번호와 페이지수를 가르쳐 줍니다. 보통의 교과서 마지막에도 책 안에 있는 중요한 단어 들의 설명이 있는 곳의 위치를
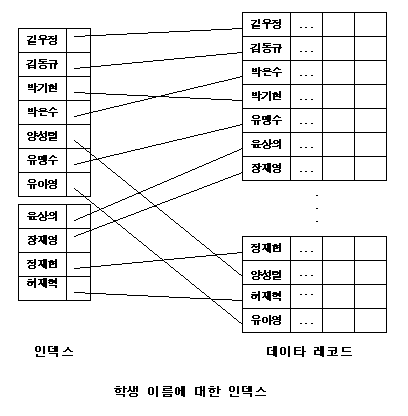
쉽게 알수 있게 하는 리스트가 포함되어있습니다. 바로 이러한 방법으로 좀더 데이타에 빠르게 접근할 수 있게 하는 것이 인덱스입니다. 그러면 데이타베이스에서 이러한 인덱스를 어떻게 이용하여 레코드를 빠르게 찾을 수 있을까요? 레코드의 한 부분, 예를 들어 학생이름에 대해서
레코드를 검색하는 경우가 많다고 할 때, 학생이름에 대해서 인덱스를 만들어 놓는다면 이름이 허 재혁인 학생을 찾을 경우 인덱스만을 찾아서 원하는
레코드를 찾을 수 있을 것입니다. 인덱스를 이용하여 레코드를 찾고자 할 때, 우선 인덱스에는 그 인덱스를 이용하는 레코드의 부분의 실제 값이 있어야 할 것이고, 인덱스가 가르키고 있는 레코드의 위치가 있어야 할 것입니다. 즉 위의 학생의 예의 경우에, 인덱스에는 학생의 이름과 그 학생의 레코드의 의치가 필요할 것입니다. 이렇게 인덱스를 구성할 경우, 인덱스에는 실제 레코드보다 휠씬 적은 양의 데이타가 들어가므로 레코드를 전부 검색할 때 보다 적은 시간에 인덱스를 검색할 수 있고 따라서 필요한 레코드를 효율적으로 찾을 수가 있습니다.
이러한 인덱스는 데이타베이스에 데이타 화일과 별도로 저장되어 있어야 하며 그 인덱스가 가르키는 레코드가 추가되거나 삭제될 경우 인덱스도
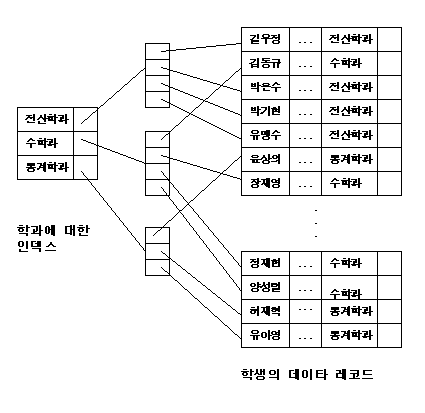
이에 맞게 추가, 삭제되어야 하며, 인덱스가 표시하는 레코드의 부분의 값이 변경되는 경우에도 인덱스를 변경시켜야 합니다. 4.2.3.2. 둘이상의 레코드를 가진 인덱스 지금까지의 인덱스는 그 인덱스가 가르키는 레코드가 하나가 있을 경우 만을 생각했는 데, 만약 하나의 인덱스에 두개 이상의 레코드가 있다면 어떻게 처리해야 할까요? 예를 들어 학생 데이타에서 학생의 소속학과부분에 대해 인덱스를 만든다면 전산과라는 인덱스에는 수십명의 학생레코드가 연결되어야 할 것입니다. 이런 경우에는 인덱스 구조에는 하나의 레코드의 위치밖에는 표시할 수 없으므로 인덱스가 직접 레코드를 가리키는 것이 아니라 인덱스와 레코드 사이에 그 인덱스에 속하는 레코드의 위치를 저장한 부분을 두고 인덱스는 이 부분을 가리키므로써 해결할 수가 있습니다.
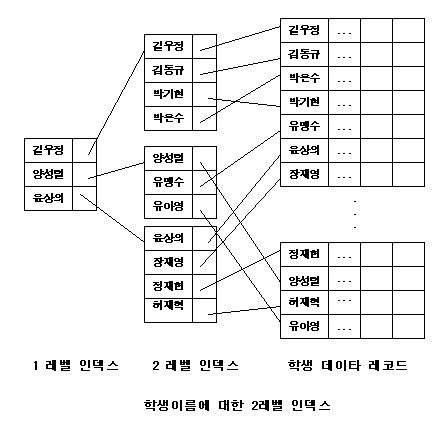
4.2.3.3. 2 레벨 이상의 인덱스 구조 레코드의 수가 증가함에 따라서 이에 대한 인덱스의 수도 증가할 것입니다. 레코드의 수가 아주 큰 경우 인덱스 구조또한 커지므로 이것들을
전부 읽어서 레코드를 찾는 것도 많은 시간이 필요하게 됩니다. 따라서 인덱스를 읽는 데에도 처음에 대이타화일에서 레코들를 찾을 때의 문제 처럼
많은 디스크 작업이 필요하게 됩니다. 이러한 경우에는 인덱스구조에 대해서 인덱스를 만들어서 전체 인덱스를 찾지 않고도 원하는 항을 찾을 수
있도록 합니다. 인덱스에 있는 값은 순서대로 나열되어 있으므로 이것을 적당하게 묶고 이렇게 묶여진 각 부분의 첫번째 인덱스의 값을 모아서 새로운 인덱스를 만든다면 2 레벨의 인덱스가 만들어 집니다. 이 2 레벨의 인덱스를 이용할 경우, 우선 첫번째 레벨에서 필요한 인덱스가 있는 위치를 찾고 그 다음에 다시 인덱스 한 묶음에서 필요한 레코드를 찾아낼 수 있습니다.
이렇게 인덱스에 대해 인덱스를 만듬으로써 인덱스의 양이 커지는 문제를 해결할 수가 있습니다. 좀더 일반적으로 확장시켜 2레벨의 인덱스
뿐만아니라 여러 레벨의 인덱스를 만들어 인덱스를 트리처럼 구성하고 이 인덱스를 따라감으로써 전체 인덱스를 읽어야하는 부담을 덜 수 가 있습니다.
|
| [목차] |